|
|
Existen similitudes entre un PC de sobremesa, un smartphone y un supercomputador, puesto que todos ellos son máquinas programables que ejecutan un sistema operativo, es decir, son lo que comúnmente conocemos como un ordenador. No obstante, cada uno de ellos tiene una arquitectura diseñada con un fin primario, buscado potencia y versatilidad en los casos del PC de sobremesa, potencia de cálculo en el supercomputador y eficiencia energética en los teléfonos móviles, puesto que no están siempre conectados a una fuente energética.
Las diferencias entre estos dispositivos se ven por ejemplo en los procesadores. El procesador ARM Cortex-A8 a 1 Ghz, que podemos encontrar por ejemplo en el smartphone Nokia N900, posee un solo un núcleo y viene a consumir 1 W, mientras que el procesador Intel Xeon E5-2620v2 a 2.1 Ghz con 6 cores consume 80 W y lo encontramos por ejemplo en el supercomputador TSUBAME-KFC que ocupa la posición 311 del la lista TOP500.org de los ordenadores más potentes del mundo, pero es el primero en la lista GREEN500, que son los superordenadores del TOP500 ordenados según su eficiencia energética.
 Este consumo eléctrico es una de las barreras a romper si se pretende llegar a la exaescala, el trillón de cálculos por segundo, una cifra de 18 ceros. Puesto que el Tianhe-2, en primer lugar del TOP500, es capaz de realizar unas 33 mil billones de cálculos por segundos, se necesitaría ser 17 veces más potente para superar la barrera antes mencionada. Este consumo eléctrico es una de las barreras a romper si se pretende llegar a la exaescala, el trillón de cálculos por segundo, una cifra de 18 ceros. Puesto que el Tianhe-2, en primer lugar del TOP500, es capaz de realizar unas 33 mil billones de cálculos por segundos, se necesitaría ser 17 veces más potente para superar la barrera antes mencionada.
Es en este punto donde nos encontramos con el problema de la exaescala, el Tianhe-2 consume la friolera de 17.8 MW que supone unos 3060 € cada hora según el precio actual de la luz 0,18€/kWh. Curiosamente a 400 Km de Changshá, ciudad donde está ubicado el Tianhe-2, se encuentra Yichang donde está la presa de las tres gargantas, la más grande del mundo, y que genera 22.500 MW.
Según estos cálculos y en una extrapolación lineal, si el Tianhe-2 que costó 280 millones de € y gasta 27 millones de € en luz al año y hacen falta 17 ordenadores como este para llegar a la exaescala, el gasto supone una inversión de unos 5000 millones de € en su fabricación y 500 millones de € en luz al año. Algo absolutamente inviable, el objetivo es llegar a la exaescala con unos parámetros de consumo similares a los actuales. Es en este punto donde nos fijamos en los procesadores ARM, ya que al consumir un 1% de los que consume un procesador actual podrían reducir considerablemente la factura de la luz. Evidentemente el de los procesadores es un ejemplo que han de seguir el resto de dispositivos electrónicos de un ordenador y que también son relevantes en el consumo eléctrico del mismo. Aunque no todo el monte es orégano, si bien nos encontramos con dificultades a la hora de integrar los ARM en supercomputación, uno de los principales inconvenientes es que no hay un lenguaje adaptado para usar dichos procesadores en supercomputación al nivel de exaescala, es más, el lenguaje de programación en general tiene que evolucionar para optimizar el uso de procesadores en los futuros superordenadores..
Se puede augurar, que en cuanto el BSC de Barcelona, que actualmente está investigando este tema, saque unas librerías de comunicación optimizadas para ARM, comenzaremos a ver cómo proliferan los supercomputadores de este tipo, lo único que hará falta será la masificación de su uso, lo cual no será tanto problema como con los actuales, ya que los costes de mantenimiento serán asequibles.
Erasmo Seebold.
Alumno del centro IEFPS Elorrieta-Erreka Mari en prácticas en el IZO-SGI.
 Cluster de cálculo Arina El Servicio General de Informática Aplicada a la Investigación (Cálculo Científico) IZO-SGI de la UPV/EHU va a instalar en breve una ampliación de su cluster de cálculo Arina con el que ofrece servicios de computación de altas prestaciones tanto a la propia universidad como a empresas u otros organismos públicos que lo demanden.
Con esta ampliación se pretende seguir ofreciendo recursos de primera línea a los investigadores para que puedan mantener su producción científica y competitividad internacional. Para ello, la ampliación trata de cubrir las necesidades que se han detectado y cubre varios aspectos de la computación al suplir de potencia de procesamiento (procesadores) y sistemas específicos de mucha memoria RAM, tarjetas gráficas de cómputo o sistemas de ficheros (discos) de alta capacidad y rendimiento. Esta ampliación se integrará totalmente en el cluster actual Arina y esperamos que en 1 mes esté totalmente operativa.
En el procedimiento mediante concurso público realizado se ha adjudicado la ampliación a la oferta realizada por Bull.
Más concretamente los elementos adquiridos son:
- 30 Nodos Blade BULLX orientados a procesamiento con las siguientes características:
- 2 Procesadores Xeon 2680v2 con 10 cores c/u.
- 128 Gb de RAM.
- Disco sólido de 128 GB.
- 1 Nodo con GPGPUs orientado a procesamiento con GPGPUs:
- 2 Procesadores Xeon 2680v2 con 10 cores c/u.
- 2 tarjetas Nvida K20.
- 128 RAM.
- Disco Solido de 128 GB
- 1 Nodo de cálculo de memoria compartida para cálculos con grandes requerimientos de memoria:
- 4 Procesadores de 8 cores c/u.
- 512 GB de RAM.
- 2 TB de disco.
- 1 Sistema de archivos paralelo de alto rendimiento basado en lustre.
- 5.8 GB/s de velocidad de Input/Output.
- 50 TB de capacidad.
- Todo unido por una red de cálculo infiniband FDR de 56 Gb/s de ancho de banda y baja latencia.
- Elementos accesorios y servicios de instalación.
Arina kalkulu klusterra UPV/EHU-ko Ikerkuntzari Zuzendutako Informatikako zerbitzu orokorrak (Kalkulu Zientifikoa) SGIker, UPV/EHU-ko HPC Arina klusterraren ahalmena handituko du. Arinak, eraginkortasun handiko baliabideak unibertsitate bera, edozein enpresa edo erakunde publikoaren esku jartzen ditu.
Handitze honekin, lehen mailako baliabideak ikertzaileen esku egonen dira, beraien ikerketa lerroak garatzen jarraitzeko, berriak zabaltzeko eta nazioarteko lehiakortasuna mantentzeko. Anpliazioak, antzemandako beharrak asetuko ditu. Honetarako, kalkulu ahalmena, RAM memoria, kalkulurako diseinatutako txartel grafikoak, eta eraginkortasun eta ahalmen handiko biltegiratze tresnak dira bereziki indartu diren osagaiak. Hau guztia, Arinan integratuko da, eta hilabete baten epean martxan egotea espero dugu.
Handitzea, lehiaketa publiko baten bidez egin da, BULL izan delarik irabazlea.
Hauek dira, modu zehatzagoan, anpliazioa osatzen duten atalak:
- 30 konputazio Nodo Blade BULLX honako ezaugarriekin:
- 10 koretako bi Xeon 2680v2 prozesagailu.
- 128 GB-etako RAMa
- 128 GB-etako disko zurrun solidoa.
- Konputazio nodo bat, K40 GPGPU batekin :
- 10 koretako bi Xeon 2680v2 prozesagailu
- 128 GB-etako RAMa
- 128 GB-etako disko zurrun solidoa.
- Memoria handiko kalkulu nodo bat:
- 8 koretako 4 Prozesagailu
- 512 GB-etako RAMa
- 2 TB-etako Disko zurruna.
- Lustren oinarritutako eraginkortasun handiko fitxategi sistema paralelo bat.
- 5.8 GB/s abiadurako S/I
- 50 TB-etako biltegiratze ahalmena.
- Guztia latentzia txikiko eta 56 Gb/s abiadurako infiniband FDR sare baten bidez lotua.
- Beste elementu txikiak eta instalazio zerbitzuak.
 The following BCAM Internship position is open at BCAM – Basque Center for Applied Mathematics, an interdisciplinary research center located in Bilbao. The research topic is free energy calculations using molecular dynamics and Monte Carlo methods. The interested applicants can apply via the following web page: The following BCAM Internship position is open at BCAM – Basque Center for Applied Mathematics, an interdisciplinary research center located in Bilbao. The research topic is free energy calculations using molecular dynamics and Monte Carlo methods. The interested applicants can apply via the following web page:
http://www.bcamath.org/en/research/internships
Internship data
Research topic title
Free energy calculations using molecular dynamics and Markov chain Monte Carlo methods.
Research topic description
Study, implementation and testing of Monte Carlo techniques combined with classical molecular dynamics (MD) with the ultimate objective of calculating protein binding energies ΔG. The project will result in a new simulation method based on the adaptation of the existing Generalized Shadow Hybrid Monte Carlo (GSHMC) to umbrella sampling. The tasks to be performed by the intern involve:
- Modifying the open-source software MD package GROMACS.
- Setting up and running simulations of biomolecular systems using the modified software on parallel computational servers.
- Analysing results and calculating ΔG using the potential of mean force curve.
Keywords
Molecular Dynamics, Hybrid Monte Carlo, Umbrella sampling, Hamiltonian dynamics.
Required knowledge and skills
Hamiltonian dynamics, Monte Carlo sampling, C programming, Unix/Linux.
Required language skills
English.
Duration and dates
2-3 months during 2014.
Application deadline
June 1st, 2014.
Supervisors
Bruno Escribano and Elena Akhmatskaya.
Research line
Modelling and Simulation in Life and Materials Sciences – M3A Research Area.
Dentro del ciclo de conferencias divulgativas “Nanotecnología: el gran reto de lo pequeño” para personas con cierta base científica pero no especializada profesor Emilio Artacho del CIC Nanogune impartirá la conferencia:
Superordenadores y física cuántica para simular sólidos, líquidos, biomoléculas y nanoestructuras. Un potentísimo microscopio virtual
Miercoles 30 de Abril a las 12:00 en la sala anexa al paraninfo de la Facultad de Ciencia y Tecnología.
 Graphene (Wikipedia) .
Introduction
Barcelona Computing Week 2014, July 7-11, at BSC/UPC, Barcelona.
 The Programming and tUning Massively Parallel Systems Summer School (PUMPS) offers researchers and graduate students a unique opportunity to improve their skills with cutting-edge techniques and hands-on experience in developing applications for many-core processors with massively parallel computing resources like GPU accelerators. The Programming and tUning Massively Parallel Systems Summer School (PUMPS) offers researchers and graduate students a unique opportunity to improve their skills with cutting-edge techniques and hands-on experience in developing applications for many-core processors with massively parallel computing resources like GPU accelerators.
Participants will have access to a multi-node cluster of GPUs, and will learn to program and optimize applications in languages such as CUDA and OmpSs. Teaching assistants will be available to help with assignments.
Important information
- Applications due: May 18
- Notification of acceptance: May 30
- Summer school dates: July 7-11, 2014
- Location: Barcelona Supercomputing Center / Computer Architecture Dept. at Universitat Politecnica de Catalunya, Barcelona, Spain
Lecturers
- Wen-mei Hwu, University of Illinois at Urbana-Champaign.
- David Kirk, NVIDIA Fellow, former Chief Scientist, NVIDIA Corporation.
- Isaac Gelado, Rosa Badia, Xavier Martorell, Jesus Labarta, Nacho Navarro (BSC and UPC).
- Rosa Badia, Xavier Martorell, Nacho Navarro (BSC and UPC).
- Teaching Assistants: Javier Cabezas, Marc Jorda, Pau Farre, Judit Planas.
The list of topics
- CUDA Algorithmic Optimization Strategies.
- Dealing with Sparse and Dynamic data.
- Efficiency in Large Data Traversal.
- Reducing Output Interference.
- Controlling Load Imbalance and Divergence.
- Debugging and Profiling CUDA Code.
- Multi-GPU Execution.
- FORTRAN Interoperability and CUDA Libraries.
- Introduction to OmpSs and to the Paraver analysis tool.
- OmpSs: Leveraging GPU/CUDA Programming.
- Hands-on Labs: CUDA Optimizations on Scientific Codes. OmpSs Programming and Tuning.
More information
Association for Computing Machinery (ACM) erakundeak ematen dituen A.M. Turing sariak, informatikako Nobel saria bezala ezagutzen dira. 2013-ko sariduna Estatu Batuetako Leslie Lamport matematikaria izan zen. Saria sakabanatutako konputazioaren arloan egindako ekarpenengatik eman diote, sakabanatutako sistemen eta aldi berekoen kalitatea, segurtasuna, koherentzia eta errendimendua hobetzeko algoritmoak eta protokoloak garatzeagatik, hain zuzen ere.
Gaur egun sakabanatutako sistemen garrantziak gora egin du, eta bere algoritmoak eta protokoloak Per to Per (P2P) elkarbanatzeko sareetan, jokalarari askotako online jokoetan, odeian, Googlen, Bing-en edo Amazon-en, Big Datako analisietan, etab topatu ditzazkegu.
 Leslie Lamport
El galardón A.M. Turing otorgado por la Association for Computing Machinery (ACM) y considerado como el Premio Nobel de la computación ha sido otorgado este 2013 al matemático estadounidense Leslie Lamport. El galardón le ha sido otorgado por su contribución en el desarrollo de algoritmos y protocolos para incrementar la calidad, seguridad, coherencia y rendimiento de los sistemas distribuidos y concurrentes.
Hoy en día debido al incremento de la importancia de los sistemas distribuidos, computación en la nube, Big Data, etc. la relevancia de sus aportaciones a la informática a aumentado. Así, podemos encontrar sus protocolos y algoritmos en los Per to Per (P2P) de intercambio de información, en los juegos multijugador online, en la nube, en buscadores como Google o Bing, Amazon, en los algoritmos de análisis de Big Data, etc.
Leslie Lamport
Ordenagailuen ahalmen handitzea etengabea izan da azken urteotan. Atzean gelditu da jada PetaFLOPS (10¹⁵ FLOPS, non FLOPSa, koma higikorreko eragiketa-kopurua segundoko, edo errazago azaltzearren, eragiketa matematiko kopurua segunduko den) potentziaren muga. Gaur egun, adituak ExaFLOPS mugarrira iristen lagunduko diguten teknologiak nolakoak izango diren begiztatzen eta garatzen dabiltza eta momentuz, badirudi, ezaguntzen dugun eta ohituta gauden teknologiaren aldean desberdina izango dela.
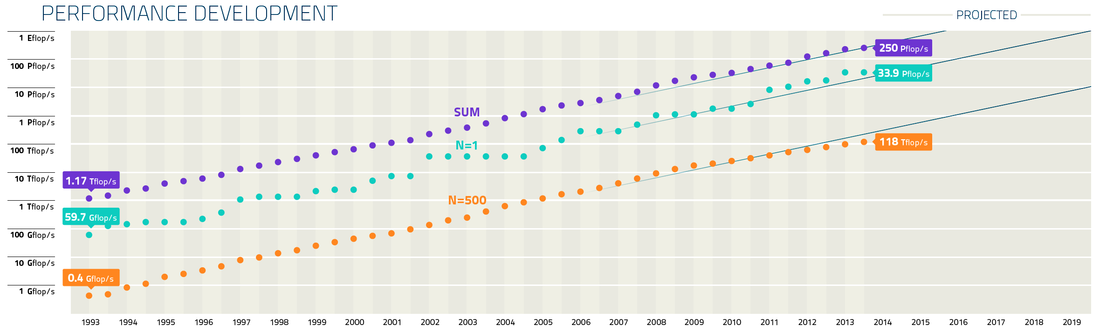 top500.org zerrendako ordenagailu ahaltsuenaren ahalmena (N=1), 500.-arena ahalmena (N=500) eta zerrenda guztiko ordenagiluen ahalamenaren batura (SUM) zerrenda atera den aldi bakoitzean.. Ordenagailuen ahalmena hasieratik handitu da esponentzialki. Joera hau Moore-en legea bezala ezagutzen da, edo honen zabalkuntza bezala ikusten da Kurzweil-en legea, “La Ley de Kurzweil, una extensión de la ley de Moore” sarreran ikusi genuen bezala. Kalkulu makinen kalkulu ahalmena esponentzialki handitu da mende hasieratik. Superkonputagailuen aro modernora mugatuz gero top500.org zerrenda aztertu dezakegu. top500.org sailakpenak LINPAC benchmark-a erabiltzen du neurri moduan eta hasieran, 1993. urtean, CM-5 ordenagailu zen ahaltsuena. Thinking Machines Corporation enpresak eraiki zuen eta Los Alamos-eko Laborategi nazionalean (EEBB) instalatu. Bere ahalmena 60 GigaFLOPS-etakoa zen (10⁹ FLOPS). 1997.-ean Sandiako Laborategi Nazionalean instalatutako Intelen ASCI Red 1.1 TeraFLOPS-etako (10¹² FLOPS) ahalmenara iritzi zen. 11 urte beranduago, Los Alamos-eko Laborategi nazionaleko IBM-ren Roadruner superkonputagailuak PetaFLOPS (10¹⁵ FLOPS) muga gainditu zuen, ASCI Red-a baino 1.000 aldiz azkarragoa. Iaz berriz, 2013. urtean, Chinako National University of Defense Technologyn dagoen Tianhe-2 superkonputagailuak 34 PetaFLOPS-etako ahalmenera iritxi zen. Honela, 2020. hamarkada hasieran espero da ExaFLOPS (10¹⁸ FLOPS) mugarrira iristea.
Superkonputagailu hauen teknologia mota aztertzen badugu, 1993. urteko CM-5 konputagailua bektoriala zela ikusiko dugu. ASCI Red berriz, 1997. urtean, prozesagailu eskalarrez eraikitako superordenagailu bat zen, eta hortik aurrera ordenagailu bektorialak indarra galtzen hasi ziren eta eskalarak irabazten. 2008. urtean berriz, Roadrunner IBM-k eraikitako superordenagailuak PetaFLOPS muga gainditzeko prozesagailu grafikoak (Play Station konsolaren Cell prozesagailuak hain zuzen ere) erabibili zituen koprozesailu matematikoa bezala, nodoen kalkulu ahalmena handitzeko. Arkitektura mota honek arrakasta izan du azken urteotan eta superkonputagailu asko prozesagailu eskalar+GPGPU-ez osatuta daude gaur egun. Honela, azken top500 zerrendan teknologia misto hau, zein orainarte gailendu izan diren prozesagailu eskalar arruntez osatuako superkonputagailuek daude aurreko postuetean. Esate baterako, Tianhe-2 superkonputagailuak bi teknologiak uztartzen ditu, baina K computer eta Sequoia superkonputagailuek prozesagailu eskalarrak bakarrik erabiltzen dituzte. Ikusi dieteken moduan, Giga, Tera edo Peta mugak gainditu zituzten teknologiak berritzaileak eta aurrekoen desberdinak izan ziren.
PetaFLOPS muga atzean utzita, adituek ExaFLOPS mugarrian jarri dute helburua. Gaur egungo teknologiaren garapen lineal batek ez duenez ExaFLOPS helburura heltzeko aukerarik ematen, ExaFLOPS hesia gainditzeko teknologia berritzaile baten bila dabiltza. Helburua, ez da noski besterik gabe, ExaFLOPS muga gaindituko duen superkonputagailu bat diseinatzea. Ikertzaileak ahalmen hori eskeini dezaken teknologiaren bila dabiltza, ondoren arruntagoak diren ordenagiluetara hedatuko litzatekeena.
Une honetan ExaFLOPS muga gainditzeko dagoen arazorik handiena energia kontsumoa da. Gaur egungo teknologia duen superkonputagailu batek ExaFLOPS muga gainditzeko, garapen lineala bat eginez (hau da prozesagailu kopurua handituz), 200 MegaWattio beharko lituzke gero martxan jartzeko. Onartezina da energia erabilera hori, 200/300 miloi $-etako kostua lukelako urtero.
Beste arazo bat, memoriaren banda zabalera da, ez baita konpuatzio ahalmena bezainbeste handitzen. Honela, prozesagailu batzuk zai geratu behar dute datuak ez baitzaizkie abiadura nahikoan irixten. Arazo hau aurkitu zuten jada Xeon prozesagailuen lehengo bertsioetan. Honekin lotutako beste bitxikeri bat: gaur egun, datu pare bat memoriatik prozesagailura mugitzeak, hauek prozesatzeak baino energia gehiago behar du.
Aurrekoa oztopoak gutxi ez balira, hurrengo hamarkadako ordenagailuek izango duten beste arazo bat prozesadore kopurua da. Horrenbeste prozesadore izango ditu, non gaur egungo programazioak eboluzionatu beharko duen prozesagailu kopuru horietan exekutatuko diren programak eraginkorrak izan daitezen. Prozesagailuak ahalik eta denbora gehien lanean egon behar dute eta ez memoriak datuak noiz pasako zai. Honeterako, superkonputagailuak dituzten ikerketa zentruek, bertan exkutatu ahal izango diren programak garatzeko esfortzu handia egiten dute, zientifikoki eta konputazionalki egokiak izan daitezken programak aukertau eta teknologia berrirako garatuz.
ExaFLOPS mailako konputazioa, punta puntako zientziak garatuz jarraituz dezan tresna eskeiniko duen erronka zientifiko eta teknologiko bat da. Modu berean, etorkizuneko konputazio eta konputagailuen nondik norakoak ezarriko ditu ziurrenik. Honengatik guztiagatik, hainbat herrialdeentzat, I+G-erako proiektu estrategiko bat da, luzerako joko duen proiektua. China, burubelarri sartu da superkonputazioaren munduan azkeneko urteotan beraiek garatutako teknologiarekin. Japonen, superkonputazioan tradizioa duen herrialdea, gobernuak eta Fujitsuk, K superkonputagailua garatu dute, ExaFLOPS mugarrira iristeko bidea ezarriz. Europan, 2011. urtean Montblanc proiektua martxan jarri zen ARM eta Bull enpresa Europearrak babestuta. EE.BB.-etan, txosten bat aurkeztu berri da kongresuan exaeskalara iristeko proiektua diseinatzeko. Bertako konputazio enpresa ugariek zeresan handia ere izango dute ere EE.BB.-etako bidean. Txostenean, proiektuaren erronka nagusiak aipatzen dira eta erakunde publikoen bultzada eta finanziziorik gabe ezingo dela exaeskalara iritxi azpimarratzen da.
————————————————————————————
Sarrera honek #KulturaZientifikoa 1. Jaialdian parte hartzen du.
OHARRA: Post hau erdaraz argitaratuta genuen aurretik hemen.
El 14 de Marzo se celebra este work shop en la escuela de ingeniería de Vitoria-Gasteiz dirigido a estudiantes, doctorandos o investigadores interesados en energía eólica. El acceso es libre.
Agenda
| 12:00-12:20. |
Apertura |
| 12:10-12:25. |
DTU Wind Energy.
Adreas Fischer, University of Denmark DTU, Department of Wind Energy. |
| 12:25-12:50. |
Research in aeroelasticity – the nieeds and the tools.
Leonardo Bergami, University of Denmark DTU, Department of Wind Energy. |
| 12:10-12:25. |
Introduction to wind turbine aeroacoustics.
Adreas Fischer, University of Denmark DTU, Department of Wind Energy. |
| 13:05-13:30. |
Discussions and conclusion. |
Más información
 Green Energy Taldea Donde: Escuela de Ingeniería de Vitoria-Gasteiz, aula S2.
Organiza: Green Energy Taldea http://www.ehu.es/get.
.
|
|
 Este consumo eléctrico es una de las barreras a romper si se pretende llegar a la exaescala, el trillón de cálculos por segundo, una cifra de 18 ceros. Puesto que el Tianhe-2, en primer lugar del TOP500, es capaz de realizar unas 33 mil billones de cálculos por segundos, se necesitaría ser 17 veces más potente para superar la barrera antes mencionada.
Este consumo eléctrico es una de las barreras a romper si se pretende llegar a la exaescala, el trillón de cálculos por segundo, una cifra de 18 ceros. Puesto que el Tianhe-2, en primer lugar del TOP500, es capaz de realizar unas 33 mil billones de cálculos por segundos, se necesitaría ser 17 veces más potente para superar la barrera antes mencionada.

Comentarios