|
|
Logwatch is a linux tool that usually runs automathicaly through cron parsing through servers logs to creates a customized report analyzing specified areas about the activity of a server.
Recently we got a new server, hereinafter NewServer, and we realized that logwatch was behaving weirdly. We were not getting the desired information as we did on other servers, hereinafter OldServer, so many information given by logwatch in other servers was not present. To make a long story short, it turned out that the /var/log/ files format (secure, syslog,...) was different. We have not identify yet where does this difference come from. It could be because the operative system in NewServer is a newer version, but why the new logwatch is not compatible? Hereinafter, you will find more information about the problem and how did we fixed it.
On one hand the information given by OldServer is shown bellow:
################### Logwatch 7.3 (03/24/06) ####################
Processing Initiated: Mon Feb 16 04:02:07 2015
Date Range Processed: yesterday
( 2015-Feb-15 )
Period is day.
Detail Level of Output: 0
Type of Output: unformatted
Logfiles for Host: OldServer
##################################################################
--------------------- sendmail-largeboxes (large mail spool files) Begin ------------------------
Large Mailbox threshold: 40MB (41943040 bytes)
Warning: Large mailbox: bsmuser (51198120)
Warning: Large mailbox: nagios (51199606)
---------------------- sendmail-largeboxes (large mail spool files) End -------------------------
--------------------- SSHD Begin ------------------------
Users logging in through sshd:
user1:
xxx.xxx.xxx.x.111: 2 times
user2:
xxx.xxx.xxx.x.119: 2 times
Received disconnect:
11: Bye Bye : 2 Time(s)
11: Closed due to user request. : 10 Time(s)
11: disconnected by user : 6 Time(s)
SFTP subsystem requests: 16 Time(s)
---------------------- SSHD End -------------------------
--------------------- Disk Space Begin ------------------------
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol01
142G 102G 34G 76% /
/dev/mapper/VolGroup00-LogVol03
95G 44G 47G 49% /opt
/dev/mapper/VolGroup00-LogVol05
98G 35G 58G 38% /usr
---------------------- Disk Space End -------------------------
Therefore, the information given by logwatch on the OldServer was just related with disk space, sshd, pam and mail services. In the other hand, in the information given by the NewServer only disk space is shown while other information was missed:
################### Logwatch 7.3.6 (05/19/07) ####################
Processing Initiated: Sun Feb 15 03:40:02 2015
Date Range Processed: yesterday
( 2015-Feb-14 )
Period is day.
Detail Level of Output: 0
Type of Output: unformatted
Logfiles for Host: OldServer
##################################################################
--------------------- Disk Space Begin ------------------------
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_n0-lv_root
188G 28G 151G 16% /
/dev/sda1 485M 81M 379M 18% /boot
/dev/mapper/vg_n0-lv_opt
375G 1.2G 355G 1% /opt
/dev/mapper/vg_n0-lv_usr
472G 29G 419G 7% /usr
/dev/mapper/vg_n0-lv_var
375G 40G 316G 12% /var
---------------------- Disk Space End -------------------------
###################### Logwatch End #########################
In the sake of clarity we are going to define the variable:
TMP_PATH=/usr/share/logwatch/scripts
We compared the logwatch filters on the different servers (/usr/share/logwatch/scripts), but all were identical, so it did not seem to be a logwatch problem, so, a deeper analysis seemed to be required in order to isolate the problem. Fortunately, this analysis turned to be quite simple because the logwatch’s “debug” option prints almost all the information that processes the command and allows you to execute it
line by line in the command line.
Part of the missed information was that related to ssh, so we choose that for debugging:
logwatch --service sendmail --range=Yesterday --debug 6
This command will print out many information on the screen but the important lines look like this:
cat /var/cache/logwatch/logwatch.aqP9adQd/secure |
perl $TMP_PATH/shared/onlyservice 'sshd' |
perl $TMP_PATH/shared/removeheaders '' |
perl $TMP_PATH/services/sshd
Knowing this, we can now run those commands on the command line. For comparison purposes, we run it on NewServer and OldServer :
cat /var/log/secure | perl $TMP_PATH/shared/onlyservice 'sshd'
The first command provided some information on OldServer but none on NewServer. onlyservice script was identical on both servers, so obviously the problem was the /var/log/secure. It turned out that the format of this file was different on NewServer and that most of the logwatch scripts where not able to deal with it.
NewServer /var/log/secure looks like this:
1424159876 2015 Feb 17 08:57:56 newserver authpriv info sshd Accepted publickey for ...
while OldServer /var/log/secure:
Feb 17 10:33:47 s_sys@oldserver sshd[14805]: Accepted password for ....
Logwatch scripts are able to process the OldServer format, but not NewServer one. The first step then was to modify the $TMP_PATH/shared/onlyservice filter. It turned out to be a perl script and adding the proper regExp fixed the firsts step. In our case we added this line:
elsif ($ThisLine =~ m/^.......... .... ... .. ..:..:.. [ ]*[^ ]* [^ ]* [^ ]* $ServiceName/io){
print $ThisLine
After this fix, we continue executing the second filter of the command:
cat /var/log/secure | perl $TMP_PATH/shared/onlyservice 'sshd' |
perl $TMP_PATH/shared/removeheaders
In this case the the filter was not removing the corresponding information, again, because the format was different. In this case, we added the following line to $TMP_PATH/shared/ remove headers
ThisLine =~ s/^.......... .... ... .. ..:..:.. .. ........ [^ ]* [^ ]* //;
Finally, we run the last filter from the command line:
cat /var/log/secure | perl $TMP_PATH/shared/onlyservice 'sshd' |
perl $TMP_PATH/shared/removeheaders |
perl $TMP_PATH/services/sshd
And now, we got a nice sshd logwatch output as the one we where getting on OldServer.
Failed logins from:
xxx.xxx.xxx.41 (xxx.xxx.xxx.es): 1 time
Illegal users from:
xxx.xxx.xxx.178 (xxx.xxx.xxx.es): 3 times
Users logging in through sshd:
user1:
xxx.xxx.xxx.254 (xxx.xxx.xxx.es): 14 times
In our case, we also modified $TMP_PATH/services/pam_unix, $TMP_PATH/services/secure/filters and added some strings to be ignored in /etc/logwatch/conf/ignore.conf.
The CEES school aims to introduce, describe and discuss the theory and applications of computational methods and tools for the study of the electronic structure of excited states in a variety of physical systems: molecules, molecular aggregates, complex systems, nanoclusters and nanoparticles, polymers and solids. The school will be taught at the postgraduate level and is specially addressed to PhD students and postdoctoral researchers with a background in electronic structure theory and its application within the quantum chemistry and/or physics fields.
 The school will take place from September 1 to September 4 2015, in San Sebastian – Donostia, at the Palacio de Miramar, located just in front of the La Concha’s bay. The school will take place from September 1 to September 4 2015, in San Sebastian – Donostia, at the Palacio de Miramar, located just in front of the La Concha’s bay.
Subjects
• Electronic structure methods for the study of electronic transitions
· Post-Hartree-Fock approaches
· Multireference approaches
· Time dependent density functional theory
· Many-body Green’s function
· Environmental effects
• Excited states in molecules
· Organic compounds
· Transition metal coordination complexes
· Lanthanide and actinide compounds
•Excited states in complex systems
· Nanoparticles
· Inorganic nanoclusters
• Excited states in extended systems
· Polymers
· Solids
Lecturers
Carlo Adamo (ENSCP-Chimie Paristech, France)
Coen de Graaf (Universitat Rovira i Virgili, Spain)
Andreas Dreuw (University of Heidelberg, Germany)
Johannes Giershner (Institute IMDEA, Spain)
Anna Krylov (University of Southern California, US)
Roland Lindh (Uppsala University, Sweden)
Oleg Prezhdo (University of Rochester, US)
Angel Rubio (UPV/EHU and DIPC, Spain)
Daniel Sanchez-Portal (UPV/EHU and DIPC, Spain)
Carsten A. Ullrich (University of Missouri, US)
Valérie Vallet (CNRS and Universite de Lille, France)
Martijn Zwijnenburg (University College London, UK)
More information
The registration fee is 150 EUROs, which covers conference material, refreshment breaks, access to all sessions and scheduled meals.
Participants of the CEES school will have the opportunity to present their scientific work on a poster.
You may also follow the updates in the social networks, concretely:
Twitter: @TheoChem_EHU (and/or using the hashtag: #CEES2015)
 R es un potente programa de estadística libre gratuito y multiplataforma. El curso se llevará a cabo en la Facultad de Ciencia y Tecnología de Leioa los días 10, 12 y 17 de Febrero. R es un potente programa de estadística libre gratuito y multiplataforma. El curso se llevará a cabo en la Facultad de Ciencia y Tecnología de Leioa los días 10, 12 y 17 de Febrero.
Datos del curso
Objetivo
Adquirir destreza en el uso del programa R a la hora de llevar a cabo análisis estadísticos y figuras.
Agenda
Martes 10 de Febrero
15:30:-19:00: Presentación general del programa R: instalación denecesarias y funcionamiento general.
17:30-19:00: Estadística descriptiva y creación de figuras.
Jueves 12 de Febrero
15:30:-19:00: Estadística paramétrica y no paramétrica en R.
17:30-19:00: Estadística multivariante (MANOVA, ACP y MDS).
Martes 17 de Febrero
17:30-19:00: Se trabajarán en R datos que traigan los alumnos.
Inscripciones
Inscripciones en el Colegio Oficial de Biólogos de Euskadi. 15 plazas como máximo. Precios consultar la información completa en el link del curso, al final.
Profesor
Dr. Aitor Larrañaga Arrizabalaga. Departamento de Biología Vegetal y Ecología, UPV/EHU
Lugar
Aula informática de la Facultad de Ciencia y Tecnología del campus de Leioa de la UPV/EHU.
Mas información
Más detalles sobre el curso en este link del Colegio Oficial de Biólogos de Euskadi.
Sobre el programa R.
According to the well known top500.org, the list of the most powerful supercomputers in the world, the supercomputing speedup is suffering an slow down. Today November 2014, the world’s most powerful computer is Tianhe-2 (Milky Way-2). This supercomputer is installed at the National University of Defense Technology (NUDT) in China and is the technological successor of Tianhe-1A, installed at the National Supercomputer Center in Tianjin, that was already No. 1 on the top500 list in November 2010.
(Nota: There is a new supercomputer more powerfull, you can read about Tianhe-2 here)
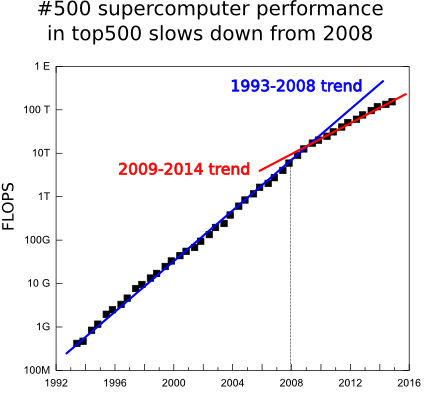 Before describing this colossus we must to mention that is the fourth consecutive time it is positioned in the first place of the top500.org semestral list, 2 years. This is an atypical situation. The computing evolves very fast and it is abnormal that in 2 years there has not been a faster supercomputer. But this is not the only worrying fact. In two years there have been only 2 new systems in the top 10 positions of the list and the age of this top 10 systems has not precedents. In addition, the power of the 500th system, the last one of the list, which use to have a smoother and continuous behavior, increased a 90% a year in the 1994-2008 range, but in the last 6 years it has dropped to a just 55% of increase. We hope this tendency will be broken soon thanks to the CORAL project in which the USA government is going to fund with 235 million dollars to build 2 pre-exascale (exaFLOPS=1000 PFLOPS) systems and with other 100 million dollars for technological development. Before describing this colossus we must to mention that is the fourth consecutive time it is positioned in the first place of the top500.org semestral list, 2 years. This is an atypical situation. The computing evolves very fast and it is abnormal that in 2 years there has not been a faster supercomputer. But this is not the only worrying fact. In two years there have been only 2 new systems in the top 10 positions of the list and the age of this top 10 systems has not precedents. In addition, the power of the 500th system, the last one of the list, which use to have a smoother and continuous behavior, increased a 90% a year in the 1994-2008 range, but in the last 6 years it has dropped to a just 55% of increase. We hope this tendency will be broken soon thanks to the CORAL project in which the USA government is going to fund with 235 million dollars to build 2 pre-exascale (exaFLOPS=1000 PFLOPS) systems and with other 100 million dollars for technological development.
 Tianhe-2 Supercomputer Tianhe-2 consists of 16,000 nodes each of which has 2 Intel Xeon Ivy Bridge processors and 3 Xeon Phi co-processors, to accelerate the calculations. This makes a total of 3,120,000 computing cores, 384,000 Xeon Ivy Bridge cores and 2,736,000 cores in the Phi coprocessors. It is a novelty that it has 3 coprocessors per node, usually there are one or two. These cores provide to Tianhe-2 a theoretical peak performance running mathematical operations of 54.9 PFLOPS (Peta = 10 ^ 15 Floating-point Operation Per Second, 1,000,000,000,000,000 mathematical operations per second) and with the LINPACK benchmark the real performance reaches 33 .9 PFLOPS, which almost doubles the previous record of the Titan supercomputer located at the Oak Ridge National Laboratory (ORNL) in Tennessee.
The interconnection network between the nodes, namely TH Express-2, is a proprietary design firstly installed in Tianhe-2 and aims to avoid communications bottlenecks implementing a bidirectional bandwidth of 16 GB/s, low latency and fat tree topology. Tianhe-2 uses the Kylin operating system based on Linux optimized for high performance computing and also developed by the NUDT. Being based on a standard Linux Kylin gives great flexibility to run many codes without specifically reprogram them.
Tianhe-2 consumes 17.8 MW, which is roughly equivalent to the consumption of 27,000 families. Nevertheless, it is energetically a very efficient supercomputer given the high number of FLOPS per watt it obtains. In the green500.org list of the energetically most efficient computers of the world Tianhe-2 is in the 32th position with 1,902 MFLOPS/W.
According to the NUDT Tianhe-2 will be dedicated to simulations, analysis and national security.
Most outstanding data
| Model |
Own design |
Nunber of cores
|
3.120.000: 384.000 Xeon Ivy-Bridge cores y 2.736.000 Phi cores |
| Processor |
Intel Xeon E-2692 with 12 cores at 2.2 GHz |
| Coprocessor |
Intel Phi 31S1P with 57 cores at 1,1 GHz |
| Interconection |
TH Express-2 |
| Operative System |
Kylin |
Theoretical FLOPS
|
54,9 PetaFLOPS |
Linpack FLOPS
|
33.9 PetaFLOPS |
Electric power
|
17.8 MW |
| FLOPS/W |
1.9 GigaFLOPS |
La nueva lista de los superordenadores más potentes del mundo muestra un estancamiento de la supercomputación a nivel mundial. De acuerdo a la nueva lista publicada hace unos días en top500.org de los ordenadores más potentes del mundo, a día de hoy Diciempbre de 2014, el ordenador más potente del mundo continua siendo el chino Tianhe-2 (Vía Láctea-2). Este superordenador está instalado en la National University of Defense Technology (NUDT) de China y es el sucesor tecnológico de Tianhe-1A, instalado en el National Supercomputer Center en Tianjin que ya fué número 1 del top500 en la lista de Noviembre de 2010.
(Nota: Ya existe un nuevo ordenador más potente, puedes leer sobre Tianhe-2 en este enlace)
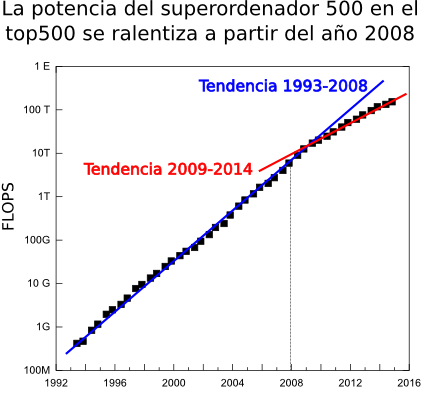 Antes de entrar a comentar los detalles técnicos de este coloso, comentar que es la cuarta vez consecutiva que ocupa el número 1 en la lista semestral del top500, es decir, lleva 2 años como el ordenador más potente del mundo. Esta es una situación atípica. La potencia de los ordenadores avanza muy rápidamente y es anormal que en 2 años no haya salido ningún nuevo superordenador que haya podido superarlo. Pero no es el único dato preocupante. Ha este dato hay que añadir, por ejemplo, que entre los 10 primeros ordenadores de esta lista apenas lleva habiendo cambios, en los dos últimos años sólo ha habido 2 nuevas entradas. La edad de los sistemas en el top10 no tiene precedentes. Otro dato claro que nos habla sobre la ralentización es que para el último sistema de la lista, la posición 500 tiene un comportamiento más suave o continuo que el número 1, el incremento en la potencia en el periodo 1994-2008 era de un 90% anual mientras que el los últimos 6 años ha sido del 55%. Esta tendencia parece que puede romper en un futuro cercano (2016-2018) pues el gobierno de EE.UU ha lanzado el proyecto CORAL con el que pretende desarrollar dos máquinas de nivel pre-exascala (exaFLOP=1000 PFLOPS) financiado con 235 millones de dolares y otros 100 millones en desarrollo tecnológico. Antes de entrar a comentar los detalles técnicos de este coloso, comentar que es la cuarta vez consecutiva que ocupa el número 1 en la lista semestral del top500, es decir, lleva 2 años como el ordenador más potente del mundo. Esta es una situación atípica. La potencia de los ordenadores avanza muy rápidamente y es anormal que en 2 años no haya salido ningún nuevo superordenador que haya podido superarlo. Pero no es el único dato preocupante. Ha este dato hay que añadir, por ejemplo, que entre los 10 primeros ordenadores de esta lista apenas lleva habiendo cambios, en los dos últimos años sólo ha habido 2 nuevas entradas. La edad de los sistemas en el top10 no tiene precedentes. Otro dato claro que nos habla sobre la ralentización es que para el último sistema de la lista, la posición 500 tiene un comportamiento más suave o continuo que el número 1, el incremento en la potencia en el periodo 1994-2008 era de un 90% anual mientras que el los últimos 6 años ha sido del 55%. Esta tendencia parece que puede romper en un futuro cercano (2016-2018) pues el gobierno de EE.UU ha lanzado el proyecto CORAL con el que pretende desarrollar dos máquinas de nivel pre-exascala (exaFLOP=1000 PFLOPS) financiado con 235 millones de dolares y otros 100 millones en desarrollo tecnológico.
Tianhe-2 Supercomputer Tianhe-2 está formado por 16.000 nodos cada uno de los cuales tiene 2 procesadores Intel Xeon Ivy Bridge y 3 coprocesadores para acelerar los cálculos Xeon Phi. Esto hace un total de 3.120.000 cores de cálculo, 384.000 Xeon y 2.736.000 cores en los coprocesadores Phi. Es una novedad que tenga 3 coprocesadores por nodo pues lo habitual son uno o dos. Estos cores le dotan de un rendimiento teórico ejecutando operaciones matemáticas de 54,9 PFLOPS (Peta=10^15 FLoating-point Operation Per Second, 1.000.000.000.000.000 operaciones matemáticas por segundo) y en el benchmark LINPACK alcanza un rendimiento real de 33,9 PFLOPS, lo cual es casi el doble que el anterior número 1 Titan.
La red de interconexión entre los nodos es un diseño propio, TH Express-2, y trata de evitar que las comunicaciones sean un cuello de botella gracias al ancho de banda bidireccional de 16 GB/s, baja latencia y topología fat tree. Tianhe-2 usa el sistema operativo Kylin, basado en Linux, y también desarrollado por la NUDT y optimizado para HPC. El hecho de estar basado en un estándar como Linux le da mucha flexibilidad a la hora de ejecutar muchos códigos sin necesidad de reprogramarlos específicamente.
Tianhe consume 17.8 MW, que equivale aproximadamente al consumo de 27.000 familias, a pesar de lo cual es también en un supercomputador muy eficiente dado el alto número de FLOPS por watio que realiza, aunque cuando se anuncie la lista green500.org de los computadores energéticamente más eficientes del mundo probablemente ocupará entorno al puesto 40.
De acuerdo a la NUDT Tianhe-2 estará dedidado a aplicaciones de simulación, análisis y seguridad nacional.
Datos más relevantes
| Marca y modelo |
Diseño propio |
| Nº de cores |
3.120.000: 384.000 cores xeon y 2.736.000 cores Phi |
| Procesador |
Intel Xeon E-2692 de 12 cores a 2.2 GHz |
| Coprocesador |
Intel Phi 31S1P de 57 cores a 1,1 GHz |
| Interconexión |
TH Express-2 |
| Sistema Operativo |
Kylin |
| FLOPS teóricos |
54,9 PetaFLOPS |
| FLOPS Linpack |
33.9 PetaFLOPS |
| Potencia eléctrica |
17.8 MW |
| FLOPS/W |
1.9 GigaFLOPS |
top500.org munduko ordenagailu ahaltsuenen zerrendaren arabera, superkonputazioaren ahalmena geldialdi batean sartu da azkeneko urteotan. Gaur egun, 2014ko Abendua, Tianhe-2 (Esne-bidea-2) da zerrendako superkonputagailu ahaltsuena. Superkonputagailu hau, Txinako National University of Defense Technology (NUDT) unibertsitatean dago eta Tianhe-1A superkonputagailuaren ondorengo teknologikoa da, azken hau, Tianjingo National Supercomputer Center-ean dago eta 2010ko Azaroko top500.org zerrendan lehengo postua lortu zuen jada.
(Nota: Badago superodenadore bat ahaltsuagoa, Tianhe-2-ri buruz irakurri dezakezu ezteka honetan)
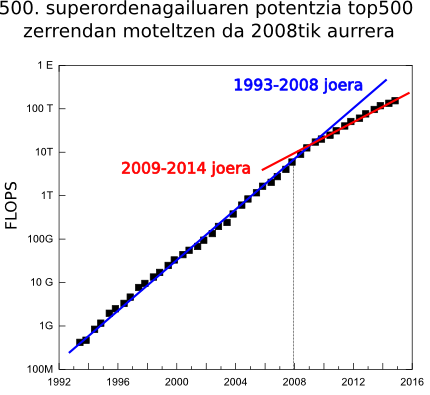 Erraldoi hau hobeto ezagutu baino lehenengo, esan behar da sei hilabetean behin eguneratzen den zerrenda honetan, Tianhe-2 superkonputagailuak bi urte jarraian daramazkila lehenengo lekuan. Hau oso arraroa da ordenagailuak oso azkar garatzen direlako, baina ez da ordenagailu ahaltsuagorik eraiki azkeneko bi urtetan. Ez da datu hau ordea kezkatzeko modukoa den bakarra. Zerrendako lehenengo hamar ordenagailuen artean, azkeneko bi urteotan bakarrik bi berri sartu dira eta top10-ean agertzen diren superordenagailuen “adinak” ez du aurrekaririk. Geldialdi hau argi eta garbi erakusten duen beste datu bat, zerrendako azken tokian dagoen superkonputagailuaren potentzia da, 500. ordenagailua alegia. Honen ahalmena, zerrendako lehenen ordenagailuarenak baino joera askoz leunagoa edo jarraiagoa du. 1994-2008 tartean, potentzia honek urtero %90-eko hazkundea izan du, baina azken 6 urtetan %55-ekoa izan da soilik. Espero dugu tendentzia hau haustea hurrengo urtetan, izan ere, EEBB-tako gobernuak CORAL proiektua jarri du martxan, “exascale” bidean (exaFLOPS=1000 PFLOPS), bi superodenagailu eraikitzeko 2017 urte inguran eta 235 milioi dolarrekin finantziatu du 100 milioi gehituz garapen teknologikorako. Erraldoi hau hobeto ezagutu baino lehenengo, esan behar da sei hilabetean behin eguneratzen den zerrenda honetan, Tianhe-2 superkonputagailuak bi urte jarraian daramazkila lehenengo lekuan. Hau oso arraroa da ordenagailuak oso azkar garatzen direlako, baina ez da ordenagailu ahaltsuagorik eraiki azkeneko bi urtetan. Ez da datu hau ordea kezkatzeko modukoa den bakarra. Zerrendako lehenengo hamar ordenagailuen artean, azkeneko bi urteotan bakarrik bi berri sartu dira eta top10-ean agertzen diren superordenagailuen “adinak” ez du aurrekaririk. Geldialdi hau argi eta garbi erakusten duen beste datu bat, zerrendako azken tokian dagoen superkonputagailuaren potentzia da, 500. ordenagailua alegia. Honen ahalmena, zerrendako lehenen ordenagailuarenak baino joera askoz leunagoa edo jarraiagoa du. 1994-2008 tartean, potentzia honek urtero %90-eko hazkundea izan du, baina azken 6 urtetan %55-ekoa izan da soilik. Espero dugu tendentzia hau haustea hurrengo urtetan, izan ere, EEBB-tako gobernuak CORAL proiektua jarri du martxan, “exascale” bidean (exaFLOPS=1000 PFLOPS), bi superodenagailu eraikitzeko 2017 urte inguran eta 235 milioi dolarrekin finantziatu du 100 milioi gehituz garapen teknologikorako.
Tianhe-2 Supercomputer Tianhe-2 16.000 nodoz osatuta dago. Nodo bakoitza bi Intel Xeon Ivy Bridge prozesagailuz eta 3 Xeon Phi koprozesagailuz, kalkulu matematikoak azkartzeko, osatuta dago. Guztira 3.120.000 kalkulu kore ditu, 384.000 Xeon koretan eta 2.736.000 Phi koretan banatuta. Hiru koprozesadore izatea berrikuntza bat da ohikoena 1 edo 2 izatea baitzen orain arte. Kore kopuru izugarri honek aplikazio matematikoak egikaritzeko 54,9 PFLOPS-etako (Peta=10^15 Floating-point Operation Per Second, 1.000.000.000.000.000 segundo bakoitzeko operazio kopurua) errendimendu teorikoa ematen dio eta LINPACK benchmarka egikaritzean 33,9 PFLOPS-etara iristen da, ia zerrendako aurreko lehenengo postua zuen Titan superordenagailuaren bikoitza.
Nodoen arteko komunikazio sarea beraiek diseinatutako elektronika darama, TH Express-2, eta komunikazioak normalean dakarren prozesuen eraginkortasuna galera saihestea du helburu. Sare hoenen ezaugarriak 16 GB/s-etako banda-zabalera bi-direkzionala, latentzia baxua eta fat tree topologia dira. Tianhe-2 superkonputagailuak Linuxen oinarritutako eta HPCrako optimizatutako Kylin sistema eragilea darama, NUDT-n garatutakoa baita ere. Linux sistema eragilean oinarrituta egoteak erraztasun asko ematen ditu programak exekutatzeko berprogramazio beharrik ez dagoelako, Linux oso zabalduta baitago zientzia arloan.
Tianhe-2 superkonputagailuak 17.8 MW elektrizitate erabiltzen ditu, gutxi gorabehera 27.000 familiek behar duten elektrizitatea. Hala ere energetikoki oso ordenagailu eraginkorra da FLOPS asko egiten baititu watio bakoitzeko, 1,902 MFLOPS/W hain zuzen ere. Izan ere energetikoki munduko ordenagailu eraginkorren green500.org zerrendan 32. postuan dago.
NUDT-ren arabera Tianhe-2 superordenagailua simulazioentzako, analisientzako eta nazioaren segurtasunerako erabiliko da.
Datu adierazgarrienak
Marka eta modeloa
|
Diseinu propioa |
Kore kopurua
|
3.120.000: 384.000 xeon kore eta 2.736.000 Phi kore |
| Procesagailua |
Intel Xeon E-2692, 12 koretakoa 2.2 GHz-etara |
| Coprocesador |
Intel Phi 31S1P, 57 koretakoa a 1,1 GHz-etara |
| Interconexioa |
TH Express-2 |
| Sistema eragilea |
Kylin |
| FLOPS teorikoak |
54,9 PetaFLOPS |
| FLOPS Linpack |
33.9 PetaFLOPS |
| Potentzia elektrikoa |
17.8 MW |
| FLOPS/W |
1.9 GigaFLOPS |
La UPV/EHU oferta el nuevo servicio de almacenamiento masivo en red ehuStorage para cubrir necesidades de la investigación y la universidad en general. El servicio se ha creado en vista de la creciente demanda de las necesidades de grandes cantidades de disco, mayormente por parte de la investigación.
Cómo funciona
El sistema es muy cómodo y sencillo. La universidad ha instalado un sistema relativamente complejo de almacenamiento en sus instalaciones, no es almacenamiento externo a la UPV/EHU en “la nube”, pero toda esta complejidad es transparente al investigador. Una vez realizada y admitida la solicitud en este almacenamiento masivo se asigna este espacio de disco en este sistema al investigador, espacio al que solo él tendrá acceso. Para acceder al disco el investigador sólo tiene que configurarlo en su ordenador (se lo podrá hacer el servicio de atención al usuario CAU) y accederá al mismo a través de la red. Cuando encendamos el ordenador se verá automáticamente como un disco más. Los técnicos podrán informarnos sobre los diferentes métodos de configurarlo según sea nuestro ordenador un PC o servidor y del sistema operativo que usemos.
 Seguridad Seguridad
La información se guarda en servidores en la UPV/EHU por lo que la información nunca sale de la UPV/EHU. Para acceder a este almacenamiento es necesario estar en la red de la universidad, bien porque el ordenador está físicamente en la misma o porque el equipo se ha conectado a la misma desde el exterior a través de VPN.
El sistema es tremendamente seguro ante fallos de hardware. Para comenzar toda la información está duplicada en dos sistemas gemelos situados en edificios diferentes. Uno de estos sistemas gemelos podría ser destruido totalmente y la información permanecería intacta en el otro. Además, cada uno de ellos posee elementos redundantes para que la rotura de discos, servidores, elementos de red, etc. no produzca una perdida de servicio ni de información.
No obstante, uno de los objetivos del proyecto es que tuviese un coste asequible, por lo que no se ha incluido un sistema de copia de seguridad. Es decir, si el investigador accidentalmente borra información esta no es recuperable. Se espera que en futuras versiones del software empleado por el sistema se incluyan los “snapshots” que permiten la recuperación de información borrada unos días tras el suceso.
Para qué es y para qué no es
El sistema se ha creado para satisfacer necesidades de almacenamiento masivo, como copias de seguridad y almacenamiento de datos, pero no necesidades de rendimiento. Es decir, en estos discos se pueden guardar gran cantidad de datos e incluso se puede trabajar sobre ellos en condiciones normales, pero no ha sido diseñado para requerimientos de gran velocidad de lectura y escritura para hacer un procesamiento intensivo de los datos. Primero, porque ello supondría un gran coste adicional, y segundo, porque a parte de los límites que tienen los propios servidores del almacenamiento están los de la red de datos, el ancho de banda y latencia de la misma que es la suma de todos los que elementos que los datos han de atravesar en su viaje desde los servidores hasta el equipo del investigador. Evidentemente va a ser más lento que un disco local de nuestro PC, pero nos va a permitir trabajar con normalidad. La excepción es el caso de que necesitemos realizar operaciones de escritura y lectura constantemente. Para este tipo de proceso de datos el Servicio de Cálculo Científico IZO-SGI tiene sistemas de almacenamiento hasta 100 veces más rápidos. Los técnicos tanto del CAU como del IZO-SGI podrán asesoraros al respecto.
Almacenamiento masivo en el Servicio de Cálculo Científico IZO-SGI
El Servicio de Cálculo Científico IZO-SGI tiene su propia instancia de este almacenamiento masivo en su cluster Arina a disposición de los investigadores. Así mismo e incluso más interesante, los investigadores pueden configurar sus instancias de almacenamiento masivo en Arina, simultáneamente a tenerla en sus propios equipos.
Más información
El servicio ehuStorage es proporcionado por la Vicegerencia de las TICs y las solicitudes han de realizarse a través del formulario correspondiente. Toda la información completa en esta web. Por ahora es un servicio gratuito pero no se descarta cobrarlo en un futuro.
The UPV/EHU offers ehuStorage a new massive storage system. The service has been setup due to the massive disk demand, mainly from the researchers.
How it works
The system is simple, from the end user point of view. However, technically the university has a set up complex file system, which is not cloud storage but local storage. Once the request of this storage space is made to the university and accepted, the space is assigned to the researcher who is the only one that can access it. To access the virtual disk the researcher has to configure it on its own computer (it can be done by the assistance of the CAU service to the user) and access it across the network. Hereafter when we power on the computer, it will automatically mount the disk. Technicians from UPV/EHU can inform you about the different methods to configure your computer depending on its characteristics.
Security
The information is stored on servers at the UPV/EHU, so the information never leaves the UPV/EHU. To access this storage, you must be in the university network, either using a computer that is physically on the university or using VPN if you are outside.
The system is extremely secure against hardware failures. Firstable, all information is duplicated in twin systems located in different buildings. One of these twin systems could be completely destroyed and information will still remain intact in the other one. In addition, different elements like disks, servers, network devices, etc. are redundant so the failure of some of them will not cause a loss of service or information.
However, one of the objectives of the project was to had an affordable cost, so it does not include a backup system. That is, if the researcher accidentally deletes information, it is not recoverable. It is expected that future versions of the software used by the system will include “snapshots” that allow information retrieval few days after it was deleted.
What it should be used for and what it should not be used for
The system is adequate to store large amount of that, like backups and scientific data, but not for high performance data access. That is, the stored data can be accessed and work on them under normal conditions, but has not been designed for requirements of high-speed read and write operations like intensive data processing. First, because this will require significant additional cost, and second, because in addition to the limits imposed on storage servers themselves there are also the limits imposed by the network, i.e., the bandwidth and latency of all the network devices the data must pass through on its journey from servers to the researcher computers. Obviously, it will be slower than a local drive of your PC, but it will allow to work normally. The exception is the case when you need to perform intensive write or read operations. For this type of data processing Scientific Computing Service IZO-SGI has storage systems 100 times faster. Technicians both CAU and the IZO-SGI may inform you about it.
Mass Storage Service IZO-SGI Scientific Computing
The Scientific Computing Service IZO-SGI has its own instance of this ehuStorage on our cluster Arina available to researchers. And even more interesting, researchers can configure its own instances of ehuStorage simultaneously in Arina and on it own computers.
More information
The ehuStorage service is provided by the ICT service (CIDIR) and applications must be made through the appropriate form. The complete information is on this web. Currently it is a free service but it can has a cost in the future.
Ehustorage service web page
UPV/EHUk, ikerkuntza eta unibertsitatearen beharrak asetzeko, sarearen bitartez atzitu daiteken edukiera handiko memoria edo disko zerbitzu berri bat martxan jarri berri du. Datuak gordetzeko (batez ere ikerkuntzaren arolokoak) beharra gero eta handiagoa izanik, Zerbitzu hau sortu da.
Nola funtzionatzen du
Sistema erabiltzailearen ikuspuntutik, erabiltzeko oso erraza eta erosoa da. Baina oinarrian, biltegiratze sistema nahiko konplexua de Unibertsiatetan bere instalazioetan eraiki duena, ez da kanpoko edo “odeian” dagoen biltegi bat. Erabiltzailearentzat ordea, konplexutasun hau estalita dago. Behin eta datua gordetzeko UPV/EHU-ri eskaera egin eta berau onartzen denan, almazenamendua esleitzen zaio ikertzaileari, espazio hori beste inork atzitu ezingo dituelarik. Ikertzaileak almazenamendua atzitzeko bere ordenagailua konfiguratu beharko du noski (EAZ/CAUk ere egin ahal dio) eta sarearen bitartez konektatuko da biltegiratze berrira. Ordenagailua piztearkoan almazenamendu hau beste disko bat bezala agertuko da. EAZ/CAU-k ere aholkatuko ditu ikertzaileak konfiguratzeko dauden era desberdinetatik ikertzailearentzat eraginkorrena zein den adieraziz.
Segurtasuna
Datuak UPV/EHUren zerbitzarietan gordetzen dira eta ez dira beraz, unibertsitateti inoiz ateratzen. Datuak atzikitzeko UPV/EHUren sarean egon behar da, UPV/EHU-tik kanpo egonda, VPN erabili behar delarik.
Sistema oso segurua da hardware matxuren aurrean. Hasteko, informazio guztia bikoiztuta dago bi sistema bikietan eta bi eraikin desberdinetan. Nahiz eta horietako sistema bat guztiz suntsitua izan, bestea mantentzen ditu zerbitzua eta datuak. Gainera, sistema bakoitzak elementu erredundanteak ditu (diskoak, sare elementuak, etab.) eta baten batek kale egiteak ez dauka eraginik erabiltzaileean aldean.
Hala ere kostua onargarria edukitzeko, ez dauka segurtasun kopiarik. Hots, erabiltzaileak nahi gabe datuak ezabatuz gero ezingo dira hauek berreskuratu. Softwarearen etorkizuneko bertsiotan “snapshot” direakoak edukitzea espero da, orduan nahi gabe ezabatutako informazioa egun batzutan zehar berreskuragarria izango da.
Zertarako da eta zertarako ez
Sistema datu kantitate handiak metatzeko sortu da, segurtasun kopiak edo ikerkuntzako datuak adibidez, baina ez eraginkortasun altua eskaintzeko. Disko hauetan datu asko gorde daitezke eta horien gainean era arruntetan lan egin, baina ez da diseinatuta izan datuak abiadura handiarekin irakurri edo idatzi ahal izateko. Alde batetik kostu oso handia suposatuko lukeelako eta bestetik biltegiratze zerbitzari hauek eman dezaketen errendimenduaren gainetik, sareak ezartzen dituen mugak zorrotzagoak daudelako. Izan ere, datuek saretik egiten duten bidean, zeharkatzen dituzten elementu guztien banda zabalera eta latentzia jasan behar dute. Memoria hau gure PCko disko bat baino mantsoagoa izango da, baina normaltasunarekin lan egin ahalko dugu. Salbuespena, datuak prozesatzeko asko irakurri eta idatzi behar baditugu izango da, prozesamendu mota honentzako IZO-SGI Kalkulu Zientifikoko Zerbitzuak almazenamendu bereziak ditu 100 aldiz azkarragoak. Bai IZO-SGIk bai CAUko teknikariak aholkatu ahalko dizuete honi buruz.
Almazenamendu masiboa IZO-SGI Kalkulo Zientifikoko Zerbitzuan
IZO-SGI Kalkulu Zientifikoko Zerbitzuak, erabiltzaileen esku, ehuStorageko bere adar propioa dauka Arina klusterrean. Gainera aukera ematen zaie ikertzaileei beraiek izan dezaketen ehuStorage almazenamendua Arinan konfiguratzeko eta horrela, bai Arinan zein bere PC-etatik datuak zuzenean atzitzeko aukera izango dute.
Informazio gehigo
EhuStorage zerbitzuak IKT gerentziaordea ematen du eta eskaerak beraiei zuzendu behar dira web orrialde honen bitartez. Momentuz doako zerbitzua da, baina ez da baztertzen etorkizun batean ordaindu behar izatea.
El curso PATC de programación en CUDA que se dará en Barcelona y pretende proporcionar conocimientos sobre programación en arquitecturas masivamente paralelas como GPUs (Nvidia y AMD) o coprocesadores (Intel Phi).
 Dónde y cuándo Dónde y cuándo
El curso lo ofrece el CUDA Center of Excellence (CCOE) concedido por Nvidia del Barcelona Supercomputing Center y la Universitat Politecnica de Catalunya en sesiones de mañana y tarde los entre los días 1 y 5 de Junio de 2015 en el Barcelona Supercomputing Center.
Objetivos
Proporcionar conocimiento y práctica sobre programación en arquitecturas masivamente paralelas como GPUs (Nvidia y AMD) o coprocesadores (Phi). La programación de estos dispositivos requiere de conocimiento sobre principios de paralelización, modelos de paralelismo y comunicación, así como sobre los límites de las propias arquitecturas. El curso está orientado a principiantes que deseen desarrollar aplicaciones para estos procesadores.
Agenda
Day 1 – 2nd June, 2015
09:00h The GPU hardware: Many-core Nvidia developments
11:15h CUDA Programming: Threads, blocks, kernels, grids
14:00h CUDA Tools: Compiling, debugging, profiling, occupancy calculator
16:15h CUDA Examples: VectorAdd, ReverseArray, Matrix Multiply
18.00h Adjourn
Day 2 – 3th June, 2015
09:00h Inside Kepler
11:15h Optimizing GPU codes on Kepler using CUDA 5.0
14:00h Lab: Getting Started Guide (PATC)
14:30h Lab: Vector Addition
16:15h Lab: Simple Matrix-Matrix Multiplication
18.00h Adjourn
Day 3 – 4th June, 2015
09:00h Future Nvidia designs: Maxwell, Pascal, Stacked DRAM
11:15h Programming with CUDA 6.0 and unified memory
14:00h Lab: Tiled 7-point 3D Stencil
16:15h Lab: Tiled Matrix-Matrix Multiplication
18.00h Adjourn
Day 4 – 5th June, 2015
09:00h Atomics and Histograming14:30h Lab: Vector Addition
11:15h Reductions
14:00h Lab: Histogramming
16:15h Lab: Vector Reduction
18.00h Adjourn
Day 5 – 6th June, 2015
09:00h Prefix Scan
11:15h CUDA Streams
14:00h Lab: Prefix scan
18.00h Adjourn
Más información
La información completa del curso y registro en la página web del curso:
http://www.bsc.es/marenostrum-support-services/hpc-education-and-training/patc-training/2015-1-5-jun-introduction-cuda
|
|
Comentarios