|
|
According to the well known top500.org, the list of the most powerful supercomputers in the world, the supercomputing speedup is suffering an slow down. Today June 2015, the world’s most powerful computer is Tianhe-2 (Milky Way-2). This supercomputer is installed at the National University of Defense Technology (NUDT) in China and is the technological successor of Tianhe-1A, installed at the National Supercomputer Center in Tianjin, that was already No. 1 on the top500 list in November 2010.
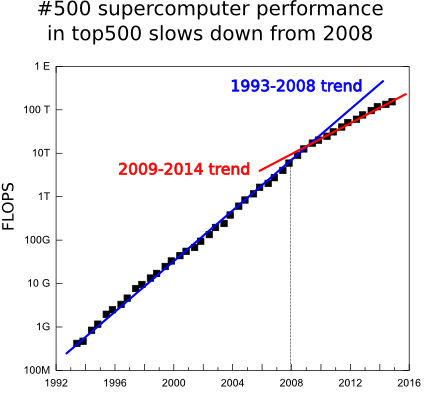 Before describing this colossus we must to mention that is the 5th consecutive time it is positioned in the first place of the top500.org semestral list, 2 years and a half, and equals the Japanese Earth Simulator(2002-2004) milestone in the list. This is an atypical situation. The computing evolves very fast and it is abnormal that in 2 years there has not been a faster supercomputer. But this is not the only worrying fact. In 4 last lists there have been only 4 new systems in the top 10 positions of the list and the age of this top 10 systems has not precedents. In addition, the power of the 500th system, the last one of the list, which use to have a smoother and continuous behavior, increased a 90% a year in the 1994-2008 range, but in the last 6 years it has dropped to a just 55% of increase. In this last list also the sum of the power of all the systems starts dropping, it mantained for few years more the previous grow due to the push of the top10 computers. We hope this tendency will be broken soon thanks to the CORAL project in which the USA government is going to fund with 235 million dollars to build 2 pre-exascale (exaFLOPS=1000 PFLOPS) systems and with other 100 million dollars for technological development. In addition, the president Obama has launched a presidential 5 year program to boost the supercomputing. Before describing this colossus we must to mention that is the 5th consecutive time it is positioned in the first place of the top500.org semestral list, 2 years and a half, and equals the Japanese Earth Simulator(2002-2004) milestone in the list. This is an atypical situation. The computing evolves very fast and it is abnormal that in 2 years there has not been a faster supercomputer. But this is not the only worrying fact. In 4 last lists there have been only 4 new systems in the top 10 positions of the list and the age of this top 10 systems has not precedents. In addition, the power of the 500th system, the last one of the list, which use to have a smoother and continuous behavior, increased a 90% a year in the 1994-2008 range, but in the last 6 years it has dropped to a just 55% of increase. In this last list also the sum of the power of all the systems starts dropping, it mantained for few years more the previous grow due to the push of the top10 computers. We hope this tendency will be broken soon thanks to the CORAL project in which the USA government is going to fund with 235 million dollars to build 2 pre-exascale (exaFLOPS=1000 PFLOPS) systems and with other 100 million dollars for technological development. In addition, the president Obama has launched a presidential 5 year program to boost the supercomputing.
 Tianhe-2 Supercomputer Tianhe-2 consists of 16,000 nodes each of which has 2 Intel Xeon Ivy Bridge processors and 3 Xeon Phi co-processors, to accelerate the calculations. This makes a total of 3,120,000 computing cores, 384,000 Xeon Ivy Bridge cores and 2,736,000 cores in the Phi coprocessors. It is a novelty that it has 3 coprocessors per node, usually there are one or two. These cores provide to Tianhe-2 a theoretical peak performance running mathematical operations of 54.9 PFLOPS (Peta = 10 ^ 15 Floating-point Operation Per Second, 1,000,000,000,000,000 mathematical operations per second) and with the LINPACK benchmark the real performance reaches 33 .9 PFLOPS, which almost doubles the previous record of the Titan supercomputer located at the Oak Ridge National Laboratory (ORNL) in Tennessee.
The interconnection network between the nodes, namely TH Express-2, is a proprietary design firstly installed in Tianhe-2 and aims to avoid communications bottlenecks implementing a bidirectional bandwidth of 16 GB/s, low latency and fat tree topology. Tianhe-2 uses the Kylin operating system based on Linux optimized for high performance computing and also developed by the NUDT. Being based on a standard Linux Kylin gives great flexibility to run many codes without specifically reprogram them.
Tianhe-2 consumes 17.8 MW, which is roughly equivalent to the consumption of 27,000 families. Nevertheless, it is energetically a very efficient supercomputer given the high number of FLOPS per watt it obtains. In the green500.org list of the energetically most efficient computers of the world Tianhe-2 is in the 32th position with 1,902 MFLOPS/W.
According to the NUDT Tianhe-2 will be dedicated to simulations, analysis and national security.
Most outstanding data
| Model |
Own design |
Nunber of cores
|
3.120.000: 384.000 Xeon Ivy-Bridge cores y 2.736.000 Phi cores |
| Processor |
Intel Xeon E-2692 with 12 cores at 2.2 GHz |
| Coprocessor |
Intel Phi 31S1P with 57 cores at 1,1 GHz |
| Interconection |
TH Express-2 |
| Operative System |
Kylin |
Theoretical FLOPS
|
54,9 PetaFLOPS |
Linpack FLOPS
|
33.9 PetaFLOPS |
Electric power
|
17.8 MW |
| FLOPS/W |
1.9 GigaFLOPS |
According to the well known top500.org, the list of the most powerful supercomputers in the world, the supercomputing speedup is suffering an slow down. Today June 2015, the world’s most powerful computer is Tianhe-2 (Milky Way-2). This supercomputer is installed at the National University of Defense Technology (NUDT) in China and is the technological successor of Tianhe-1A, installed at the National Supercomputer Center in Tianjin, that was already No. 1 on the top500 list in November 2010.
Before describing this colossus we must to mention that is the 5th consecutive time it is positioned in the first place of the top500.org semestral list, 2 years and a half, and equals the Japanese Earth Simulator(2002-2004) milestone in the list. This is an atypical situation. The computing evolves very fast and it is abnormal that in 2 years there has not been a faster supercomputer. But this is not the only worrying fact. In 4 last lists there have been only 4 new systems in the top 10 positions of the list and the age of this top 10 systems has not precedents. In addition, the power of the 500th system, the last one of the list, which use to have a smoother and continuous behavior, increased a 90% a year in the 1994-2008 range, but in the last 6 years it has dropped to a just 55% of increase. In this last list also the sum of the power of all the systems starts dropping, it mantained for few years more the previous grow due to the push of the top10 computers. We hope this tendency will be broken soon thanks to the CORAL project in which the USA government is going to fund with 235 million dollars to build 2 pre-exascale (exaFLOPS=1000 PFLOPS) systems and with other 100 million dollars for technological development. In addition, the president Obama has launched a presidential 5 year program to boost the supercomputing.
Tianhe-2 Supercomputer Tianhe-2 consists of 16,000 nodes each of which has 2 Intel Xeon Ivy Bridge processors and 3 Xeon Phi co-processors, to accelerate the calculations. This makes a total of 3,120,000 computing cores, 384,000 Xeon Ivy Bridge cores and 2,736,000 cores in the Phi coprocessors. It is a novelty that it has 3 coprocessors per node, usually there are one or two. These cores provide to Tianhe-2 a theoretical peak performance running mathematical operations of 54.9 PFLOPS (Peta = 10 ^ 15 Floating-point Operation Per Second, 1,000,000,000,000,000 mathematical operations per second) and with the LINPACK benchmark the real performance reaches 33 .9 PFLOPS, which almost doubles the previous record of the Titan supercomputer located at the Oak Ridge National Laboratory (ORNL) in Tennessee.
The interconnection network between the nodes, namely TH Express-2, is a proprietary design firstly installed in Tianhe-2 and aims to avoid communications bottlenecks implementing a bidirectional bandwidth of 16 GB/s, low latency and fat tree topology. Tianhe-2 uses the Kylin operating system based on Linux optimized for high performance computing and also developed by the NUDT. Being based on a standard Linux Kylin gives great flexibility to run many codes without specifically reprogram them.
Tianhe-2 consumes 17.8 MW, which is roughly equivalent to the consumption of 27,000 families. Nevertheless, it is energetically a very efficient supercomputer given the high number of FLOPS per watt it obtains. In the green500.org list of the energetically most efficient computers of the world Tianhe-2 is in the 32th position with 1,902 MFLOPS/W.
According to the NUDT Tianhe-2 will be dedicated to simulations, analysis and national security.
Most outstanding data
| Model |
Own design |
Nunber of cores
|
3.120.000: 384.000 Xeon Ivy-Bridge cores y 2.736.000 Phi cores |
| Processor |
Intel Xeon E-2692 with 12 cores at 2.2 GHz |
| Coprocessor |
Intel Phi 31S1P with 57 cores at 1,1 GHz |
| Interconection |
TH Express-2 |
| Operative System |
Kylin |
Theoretical FLOPS
|
54,9 PetaFLOPS |
Linpack FLOPS
|
33.9 PetaFLOPS |
Electric power
|
17.8 MW |
| FLOPS/W |
1.9 GigaFLOPS |
La nueva lista de los superordenadores más potentes del mundo muestra un estancamiento de la supercomputación a nivel mundial. De acuerdo a la nueva lista publicada hace unos días en top500.org de los ordenadores más potentes del mundo, a día de hoy Junio de 2015, el ordenador más potente del mundo continua siendo el chino Tianhe-2 (Vía Láctea-2). Este superordenador está instalado en la National University of Defense Technology (NUDT) de China y es el sucesor tecnológico de Tianhe-1A, instalado en el National Supercomputer Center en Tianjin que ya fué número 1 del top500 en la lista de Noviembre de 2010.
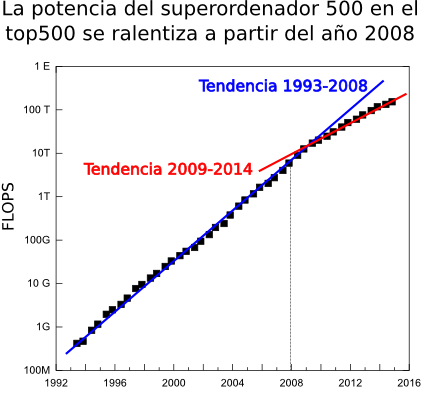 Antes de entrar a comentar los detalles técnicos de este coloso, comentar que es la quinta vez consecutiva que ocupa el número 1 en la lista semestral del top500, es decir, lleva 2 años y medio como el ordenador más potente del mundo e iguala el hito del Earth Simulator japones (2002-2004). Esta es una situación atípica. La potencia de los ordenadores avanza muy rápidamente y es anormal que en 2 años no haya salido ningún nuevo superordenador que haya podido superarlo. Pero no es el único dato preocupante. Ha este dato hay que añadir, por ejemplo, que entre los 10 primeros ordenadores de esta lista apenas lleva habiendo cambios, en las 4 últimas listas sólo ha habido 4 nuevas entradas. La edad de los sistemas en el top10 no tiene precedentes. Otro dato claro que nos habla sobre la ralentización es que para el último sistema de la lista, la posición 500 tiene un comportamiento más suave o continuo que el número 1, el incremento en la potencia en el periodo 1994-2008 era de un 90% anual mientras que el los últimos 6 años ha sido del 55%. En la última lista se aprecia también que la suma de la potencia de los 500 sistemas de la lista se ralentiza dado que durante los primeros años en los que se empezó a notar el cambio de tendencia en la cola de la lista en global aún se mantenía el crecimiento debido a los nuevos superordenadores en la parte alta. Esta tendencia parece que puede romper en un futuro cercano (2016-2018) pues el gobierno de EE.UU ha lanzado el proyecto CORAL con el que pretende desarrollar dos máquinas de nivel pre-exascala (exaFLOP=1000 PFLOPS) financiado con 235 millones de dolares y otros 100 millones en desarrollo tecnológico y el Presidente Obama a lanzado una iniciativa a cinco años para impulsar la supercomputación. Antes de entrar a comentar los detalles técnicos de este coloso, comentar que es la quinta vez consecutiva que ocupa el número 1 en la lista semestral del top500, es decir, lleva 2 años y medio como el ordenador más potente del mundo e iguala el hito del Earth Simulator japones (2002-2004). Esta es una situación atípica. La potencia de los ordenadores avanza muy rápidamente y es anormal que en 2 años no haya salido ningún nuevo superordenador que haya podido superarlo. Pero no es el único dato preocupante. Ha este dato hay que añadir, por ejemplo, que entre los 10 primeros ordenadores de esta lista apenas lleva habiendo cambios, en las 4 últimas listas sólo ha habido 4 nuevas entradas. La edad de los sistemas en el top10 no tiene precedentes. Otro dato claro que nos habla sobre la ralentización es que para el último sistema de la lista, la posición 500 tiene un comportamiento más suave o continuo que el número 1, el incremento en la potencia en el periodo 1994-2008 era de un 90% anual mientras que el los últimos 6 años ha sido del 55%. En la última lista se aprecia también que la suma de la potencia de los 500 sistemas de la lista se ralentiza dado que durante los primeros años en los que se empezó a notar el cambio de tendencia en la cola de la lista en global aún se mantenía el crecimiento debido a los nuevos superordenadores en la parte alta. Esta tendencia parece que puede romper en un futuro cercano (2016-2018) pues el gobierno de EE.UU ha lanzado el proyecto CORAL con el que pretende desarrollar dos máquinas de nivel pre-exascala (exaFLOP=1000 PFLOPS) financiado con 235 millones de dolares y otros 100 millones en desarrollo tecnológico y el Presidente Obama a lanzado una iniciativa a cinco años para impulsar la supercomputación.
Tianhe-2 Supercomputer Tianhe-2 está formado por 16.000 nodos cada uno de los cuales tiene 2 procesadores Intel Xeon Ivy Bridge y 3 coprocesadores para acelerar los cálculos Xeon Phi. Esto hace un total de 3.120.000 cores de cálculo, 384.000 Xeon y 2.736.000 cores en los coprocesadores Phi. Es una novedad que tenga 3 coprocesadores por nodo pues lo habitual son uno o dos. Estos cores le dotan de un rendimiento teórico ejecutando operaciones matemáticas de 54,9 PFLOPS (Peta=10^15 FLoating-point Operation Per Second, 1.000.000.000.000.000 operaciones matemáticas por segundo) y en el benchmark LINPACK alcanza un rendimiento real de 33,9 PFLOPS, lo cual es casi el doble que el anterior número 1 Titan.
La red de interconexión entre los nodos es un diseño propio, TH Express-2, y trata de evitar que las comunicaciones sean un cuello de botella gracias al ancho de banda bidireccional de 16 GB/s, baja latencia y topología fat tree. Tianhe-2 usa el sistema operativo Kylin, basado en Linux, y también desarrollado por la NUDT y optimizado para HPC. El hecho de estar basado en un estándar como Linux le da mucha flexibilidad a la hora de ejecutar muchos códigos sin necesidad de reprogramarlos específicamente.
Tianhe consume 17.8 MW, que equivale aproximadamente al consumo de 27.000 familias, a pesar de lo cual es también en un supercomputador muy eficiente dado el alto número de FLOPS por watio que realiza, aunque cuando se anuncie la lista green500.org de los computadores energéticamente más eficientes del mundo probablemente ocupará entorno al puesto 40.
De acuerdo a la NUDT Tianhe-2 estará dedidado a aplicaciones de simulación, análisis y seguridad nacional.
Datos más relevantes
| Marca y modelo |
Diseño propio |
| Nº de cores |
3.120.000: 384.000 cores xeon y 2.736.000 cores Phi |
| Procesador |
Intel Xeon E-2692 de 12 cores a 2.2 GHz |
| Coprocesador |
Intel Phi 31S1P de 57 cores a 1,1 GHz |
| Interconexión |
TH Express-2 |
| Sistema Operativo |
Kylin |
| FLOPS teóricos |
54,9 PetaFLOPS |
| FLOPS Linpack |
33.9 PetaFLOPS |
| Potencia eléctrica |
17.8 MW |
| FLOPS/W |
1.9 GigaFLOPS |
En el Servicio de Cálculo Científico de la UPV/EHU (IZO-SGI) creemos que podemos ser un firme apoyo para tus solicitudes de fondos en proyectos de investigación que involucren computación científica dada la calidad y reputación del Servicio. La política europea en materia de computación impulsa el acceso a recursos de computación abiertos y compartidos como los del IZO-SGI, en contraposición a recursos monopolizados por usuarios individuales.
Desde este punto de vista hemos redactado en detalle datos técnicos y de gestión de nuestro Servicio que podrían ser interesantes para incluir en una solicitud de fondos para acceso a infraestructura de computación. Para cualquier pregunta, solicitud o aclaración no dudes en ponerte en contacto con nosotros.
No tengas reparos en copiar, resumir o adaptar este texto a tus solicitudes.
Introducción
El Servicio General de Informática Aplicada a la investigación (Cálculo Científico), en adelante IZO-SGI, está adscrito en los Servicios Generales de Investigación (SGIker) de la UPV/EHU. El Servicio de Cálculo IZO-SGI ofrece acceso a recursos computacionales de altas prestaciones, software y soporte de calado y entidad. Presta servicio a toda la comunidad científica, en particular a los investigadores de la UPV/EHU (principal institución de investigación en Euskadi), pero además está accesible a toda la comunidad científica y empresarial. El IZO-SGI dispone desde 2004 de un cluster de computación completo que ha ido ampliando regularmente para satisfacer la creciente demanda de un amplio espectro de grupos de investigación que abarcan todas las áreas de la Ciencia (Física, Química, Ingeniería, Informática, Matemáticas, Biología, Geología, Economía, etc).
Infraestructura
Un cluster de cálculo de altas prestaciones no es equipamiento informático al uso, es equipamiento científico complejo que requiere personal cualificado y específico para su gestión, además de estar ubucado en un lugar que grantice su óptimo funcionamiento y rendimiento.
El cluster ha sido diseñado por los miembros del Servicio de Cálculo IZO-SGI como una única infraestructura totalmente integrada, pero cuya heterogeneidad lo convierte en una herramienta válida para satisfacer las necesidades de un amplio espectro de investigaciones en cualquiera de las áreas de la Ciencia, como lo demuestra las investigaciones en las que se emplea. En concreto se dispone de:
- Política de ampliación y renovación bienal.
- 3.728 cores de cálculo en nodos 212 nodos, 10 de arquitectura IA64 y 202 x86-64 que permiten la ejecución de cálculos estándar y de uso masivo de cpu.
- 6 nodos con 2 GPGPUs Nvidia Tesla por nodo para extraer el máximo rendimiento a programas que explotan de forma muy eficiente esta nueva tecnología.
- Nodos con gran memoria RAM para trabajos con estos requerimientos, hasta un máximo de 512 GB de RAM por nodo.
- Sistemas de ficheros de alto rendimiento con gran capacidad y velocidad de lectura/escritura basados en Lustre. 3 sistemas diferentes con hasta 40 TB y hasta 7 GB/s de velocidad en lectura y escritura.
- Todo interconectado por una red de alto ancho de banda y baja latencia infiniband, la última ampliación infiniband FDR de 56 Gb/s de ancho de banda.
- Servidores de gestión en alta disponibilidad para garantizar una operación 24h*365 días.
- Todo instalado en el Centro de Proceso de Datos (CPD) de la UPV/EHU con toda una variedad de sistemas para garantizar un funcionamiento óptimo (ver siguiente punto para los detalles del CPD).
Para ver detalles técnicos más concretos visitar el apartado de recursos computacionales de la página web del IZO-SGI.
Además, la concentración de recursos materiales y humanos en el Servicio de Cálculo IZO-SGI ha creado un comunidad y permite acceder a los grupos a recursos cualitativa y cuantitativamente superiores en todos los sentidos con la consiguiente mejora de los resultados. El aprovechamiento y amortización de la infraestructura y costes secundarios asociados a la misma es extremadamente eficiente y eficaz.
Ubicación, CPD o centro de datos
El equipamiento se instala en el Centro de Proceso de Datos (CPD) de la UPV/EHU. El CPD de 450 m² y de nueva construcción, en 2006, es un lugar habilitado para la ubicación de computadores y está capacitado con todos los sistemas necesarios para garantizar el correcto funcionamiento de ellos. Dispone de:
- Sistemas de climatización de precisión por expansión directa exclusivo y sistema de descalcificación del agua. Los 7 aparatos de aire acondicionado con una potencia agregada de 208KW, lo que asegura una redundancia N+1 ante posibles fallos.
- Sistema contraincendios. Sistema de detección de incendios mediante detectores ópticos y térmicos. Sistema de extinción por agua nebulizada HI-FOG, que preserva la integridad del equipamiento informático en caso de activación.
- Acometida desde dos transformadores independientes.
- Doble rama eléctrica para los equipos IT, cada una con SAIs (sistemas de alimentación ininterrumpida) independiente y cuadros de baja tensión independientes. Permite redundancia y mantenimiento en caliente de la instalación eléctrica.
- Grupo electrógeno de 750 KVA con dos días de autonomía sin necesidad de repostar.
- Control de acceso, alarmas y vigilancia mediante circuito cerrado de TV.
- Copias de seguridad de datos y sistemas de las máquinas.
- Monitorización por parte de operadores in-situ y sistema de gestión y control de las instalaciones.
- Metodología 5S para la mejora de la calidad.
Los equipamientos están monitorizados in-situ e informáticamente y tiene los mantenimientos y en regla con revisiones periódicas incluídas.
La Vicegerencia de las TICs dispone en otro edificio incluso de un CPD secundario de respaldo del primer CPD donde mantiene duplicados los servicios básicos para en caso de grave desastre poder mantener la operativa. Por ejemplo, las copias de seguridad se realizan en este CPD secundario para mantener separados los datos y sus copias de seguridad.
Esta moderna infraestructura permite un funcionamiento ininterrumpido 24h*7 días de las máquinas tremendamente estable.
Otros servicios
La Vicegerencia de las TICs mantiene la red de datos de la UPV/EHU que está formada por tecnologías de primera línea y de última generación. Esto permite que se puedan establecer conexiones con gran ancho de banda (hasta 10Gbps) y un alto grado de seguridad, algo fundamental para trabajar con eficacia en una infraestructura a la que hay que conectarse remotamente. La red dispone de elementos hardware redundantes y líneas de comunicación duplicadas con caminos diversificados, así como firewall perimetral, zonas de red desmilitarizadas, balanceadoras, sistemas hardware de detección de orígenes inseguros o potencialmente peligrosos, etc. La conexión con Internet, hacia el exterior, se realiza a través de i2Basque, la red de datos autonómica, que a su vez conecta con RedIRIS, la red académica y de investigación Española.
Dentro de los servicios de investigación que ofrece la Vicegerencia de las TICs cabe destacar por su relevancia para la computación de altas prestaciones la de un sistema de almacenamiento masivo para investigadores integrable en el Servicio. Este es altamente seguro al existir, entre otras medidas, una copia de respaldo en el CPD secundario y es escalable en capacidad y ancho de banda para satisfacer las necesidades actuales y futuras.
Personal
Personal técnico específico
Un cluster de cálculo de HPC no es equipamiento científico normal sino equipamiento científico puntero y complejo. El diseño y gestión específica y particular que requiere el entorno de cálculo está gestionado por dos doctores en Química y Física con amplia experiencia en HPC, dos de las áreas científicas que más uso hacen de la computación de altas prestaciones, lo que les permite ofrecer un servicio de asesoramiento científico de alto valor añadido. Llevan al frente del Servicio desde 2004 y ya tenían experiencia previa en gestión de entornos HPC y durante sus respectivas tesis doctorales hicieron uso de cálculo intensivo.
Además, se cuenta con el soporte técnico de la Vicegerencia de las TICs, el técnico-administrativo de los SGIker y el general de la UPV/EHU. Hau ez da infraestructura.
La estructura administrativa del SGIker de la UPV/EHU, 12 personas, se encarga de las tareas administrativas como gestión económica, dirección y administración general. Los SGIker disponen de unidades que también dan apoyo interno como son el Servicio de Calidad e Innovación, el de Cienciometría y el de infraestructura.
Personal técnico no específico
Un director científico con amplia experiencia, conocimientos y visión de la computación de altas prestaciones en general y en el campo de la química computacional en particular guía al servicio en la toma de decisiones estratégicas.
La Vicegerencia de las Tecnologías de la Información y la Comunicación es el mayor departamento de la UPV/EHU por personal. El personal dedicado a tareas informáticas supera con creces las 150 personas. El IZO-SGI mantiene un estrecho contacto y colaboración con diversas áreas de la Vicegerencia de las TICs:
- Con el área de explotación que se encarga del mantenimiento de servicios, equipamiento, monitorización, etc de los que hace uso el IZO-SGI.
- Con el área de redes para habilitar los servicios de red, puertos, reglas, etc que se requieren para el correcto funcionamiento de hardware y software del IZO-SGI y la conexión remota de los investigadores a nuestros clusters.
- Con el área aulas docentes que nos apoya en la gestión del GRID Péndulo que usa las aulas docentes por la noche para cálculo científico. También para la instalación de software que gestiona el IZO-SGI que se usa para docencia además de para investigación.
- Con el área de atención al usuario, que resuelve problemas a los investigadores en su puesto local que por su tipología puede ser resuelto más eficazmente por un técnico informático in-situ, como por ejemplo la instalación de software en sus equipos personales.
Al estar integrados en la UPV/EHU disponemos de todos los servicios que esta ofrece con el personal asociado a la misma y perteneciente a la propia estructura administrativa y técnica de la UPV/EHU.
Póliticas de calidad y evaluación
Los SGIker, están volcados con la calidad y tienen definida la política de calidad que sirve de marco de referencia en el establecimiento de los objetivos, metas y programas de calidad implantados. La calidad de los servicios ofrecidos es la piedra angular de la competencia investigadora y productiva, y por lo tanto, de los SGIker. Prueba de este compromiso es la existencia de la Unidad de Calidad e Innovación que centra sus esfuerzos en la implantación, mantenimiento y mejora continua de un Sistema de Gestión de la Calidad basado en Normas Internacionales y con reflejo en la plataforma documental del sistema de gestión de calidad.
La Unidad de Calidad e Innovación de los SGIker realiza todos los años de forma independiente y entre los investigadores usuarios una encuesta de satisfacción del IZO-SGI. El IZO-SGI ha obtenido en 2014 una valoración de 9.6 y tiene una media en los últimos 5 años de 9.1.

Registration
The early registration discount applies if you register before June 30th, and you can do so by clickin ghere. For additional information regarding the UGM, please visit the event page.
Poster Session
If you would like to present an application of the Schrödinger suite from your work, there are a few poster slots still available and we’re welcoming submissions for review. Simply e-mail the title and 1-page abstract directly to 2015_europe_ugm@schrodinger.biz.
Hands-On Workshops
#1 – Introduction to Molecular Dynamics with Desmond
- Introduction to Molecular Dynamics
- Prepare a simulation in less than 10 minutes
- Analysis and interpretation of MD results: What can I learn from a MD simulation?
- Focus on proteins and protein-ligand systems
#2 – Quantum Mechanics: Where it makes a difference in drug discovery
- Geometry optimizations and scans in drug-like molecules and metal clusters
- Reactivity and toxicity predictions
- pKa predictions
- Hydrogen bond strength and non-covalent interactions
#3 – Lead Optimization: From micromolar to nanomolar inhibitors via accurate free binding energy predictions
- Recreate a fragment-based drug design study of JAK-2 inhibitors using FEP+
- Prepare a system for FEP calculations: Ligand alignments, water treatment, and dealing with X-ray structures
- Analyze FEP results with new tools: Extending calculations to new design ideas
- Other applications of FEP: Predictions of solubility, selectivity, off-target activity, and protein stability
#4 – Increasing the impact of modelling on drug discovery with Schrödinger Enterprise Informatics
- Query the Protein Ligand Database (PLDB) for novel interaction motifs
- Share results from Maestro with other colleagues using LiveDesign
- Publish a validated computational model
- Collaborative design
More Information here
El superodenador Sunway TaihuLight es el nuevo superordenador más potente del mundo. Este superordenador chino ha relegado al segundo lugar de la lista de supercomputadoras más potentes del mundo top500.org al también chino Tianhe-2, que ha permanecido 6 listas consecutivas (se actualiza semestralmente) como la supercomputadora más potente del mundo
Sunway TaihuLight tiene un rendimiento teórico de 125 PetaFLOPS y un rendimiento real de 93 PetaFLOPS con el benchmark HPL (High Performance Linpack) lo que representa una eficiencia del 74%. Con esto casi triplica el rendimiento de su antecesor el Tianhe-2 (34 PetaFLOPS y una eficiencia del 62%) con además una eficiencia superior.
 Uno de los hitos más importantes de Sunway TaihuLigth es que está construido con tecnología 100% china, entre ellas el procesador el SW26010, con lo que consigue la independencia tecnológica de EE.UU. SunWay TaihuLight no usa coprocesadores sino 40.960 nodos, con 4 procesadores cada nodo, con 64 cores de cómputo más otro de gestión que también participa del cálculo para un total de más de 10,5 millones de cores. No obstante, Sunway TaihuLight a causa de su acceso a memoria y su red de comunicación tiene un rendimiento más pobre en el bechmark más actual HPCG (High Performance Conjutate Gradients), donde incluso el Tianhe-2 lo supera, lo que puede suponer que no sea tan eficaz corriendo un espectro más amplio de aplicaciones. No obstante, si hay software que se ha desarrollado paralelamente al proyecto del hardware y que corre muy eficientemente en Sunway TaihuLigth. Uno de los hitos más importantes de Sunway TaihuLigth es que está construido con tecnología 100% china, entre ellas el procesador el SW26010, con lo que consigue la independencia tecnológica de EE.UU. SunWay TaihuLight no usa coprocesadores sino 40.960 nodos, con 4 procesadores cada nodo, con 64 cores de cómputo más otro de gestión que también participa del cálculo para un total de más de 10,5 millones de cores. No obstante, Sunway TaihuLight a causa de su acceso a memoria y su red de comunicación tiene un rendimiento más pobre en el bechmark más actual HPCG (High Performance Conjutate Gradients), donde incluso el Tianhe-2 lo supera, lo que puede suponer que no sea tan eficaz corriendo un espectro más amplio de aplicaciones. No obstante, si hay software que se ha desarrollado paralelamente al proyecto del hardware y que corre muy eficientemente en Sunway TaihuLigth.
China desbanca a EE.UU en el Top500
En la lista de Junio de 2016 es la primera vez en la historia del Top500 que EE.UU no es el país con el mayor número de sistemas instalados. En esta lista dispone de 165 sistemas que supera China con 167 supercomputadoras. China también es el país que más rendimiento aglutina en toda la lista, gracias especialmente a los dos superordenadores que tiene como números 1 y 2 de la lista.
Este vídeo nos muestra como el HPC ayuda a los artistas a realizar películas de animación 3D más realistas como podemos ver en las películas de Disney Frozen, Enredados o Big Hero 6. En las películas de animación 3D muchos de los movimientos de los objetos no se dibujan arbitrariamente sino que se rigen y calculan con leyes físicas programadas por ordenador. Así mismo se definen las propiedades físicas de las superficies y la posición de los focos de luz y la escena se ilumina calculando las trayectorias de los rayos de luz, un proceso tremendamente complejo.
https://youtu.be/-7Bpo1Quxyw?list=PLyZk_jpQ4X_pLxg2K_dk1NzBFdfeeii9e
Este vídeo nos muestra como desde pasta de dientes a pañales o detergente, compañías como Procter&Gamble usan Computación de Altas Prestaciones para crear productos mejores, más eficientes, más competitivos, rentables y servicios para mejorar nuestra vida cotidiana.
https://youtu.be/PuCx50FdSic?list=PLyZk_jpQ4X_pLxg2K_dk1NzBFdfeeii9e
The NSCCS will hold a 2 day workshop on TURBOMOLE, a powerful, general purpose Quantum Chemistry program package for ab initio electronic structure calculations from 22nd to 23rd September 2015 at Imperial College London.
Scope of the workshop
This two day workshop will introduce researchers in the field of quantum chemical calculations to TURBOMOLE in general and the graphical user interface, command line usage and special general topics like parallelisation, queuing systems, and other technicalities. On the afternoon of the second day we may discuss a few special topics the participants may choose.
 List of topics List of topics
- Introduction
- Using the graphical user interface of TURBOMOLE
- Command line usage
- Command line tools
- Running parallel jobs
- Special topics requested by participants
Target audience
Attendees are expected to be graduate students and postdocs as well as young lecturers who have limited experience in quantum chemical calculations and/or TURBOMOLE and would benefit from an introductory workshop.
Important data
Date and place of the workshop: Tuesday 22nd to Wednesday 23rd September 2015 at Imperial College London.
Application deadline: 2pm, Tuesday 1st September 2015
Fee: 60 GBP for Non-UK and Non-Academic attendees.
More information and application
NSCCS this web page.
Un techo de cristal es una barrera que impide o limita el desarrollo o crecimiento pero que no se percibe. En computación también podemos encontrar un techo de cristal que impide el desarrollo potencial de una mejor I+D+i. El origen primero de este techo de cristal es la falta de una profesionalización del cálculo científico como actividad. La falta de recursos adecuados es un techo bien palpable por el investigador. No obstante, el efecto indirecto en su investigación a veces puede pasar desapercibido debido debido a los mecanismos subconscientes de nuestro cerebro para descartar posibilidades. Es decir, la palpable y directa ausencia de recursos suficientes genera un techo en nuestra investigación, pero no siempre se es consciente de su existencia, no se visualiza como una barrera y por tanto se plantea como obstáculo a superar.
¿Dónde está el techo de cristal?
 Para encontrarlo partamos de la situación más típica que es cuando un investigador empieza a computar, a realizar cálculo científico. Evidentemente todos los investigadores tienen un PC en el que han realizado pequeños cálculos con hojas de cálculo, gráficos, etc. por lo que empezar a calcular en ese mismo PC es algo natural, de hecho en muchos casos los primeros cálculos suelen ser más sencillos y perfectamente ejecutables de forma casi inmediata en los PCs. No obstante, suele seguir un proceso de profundización y crecimiento de la complejidad que puede llevarnos al hecho que comenzamos a percibir que nuestro PC tiene unas limitaciones, y eso por supuesto es una limitación para el desarrollo de nuestra I+D+i. Para encontrarlo partamos de la situación más típica que es cuando un investigador empieza a computar, a realizar cálculo científico. Evidentemente todos los investigadores tienen un PC en el que han realizado pequeños cálculos con hojas de cálculo, gráficos, etc. por lo que empezar a calcular en ese mismo PC es algo natural, de hecho en muchos casos los primeros cálculos suelen ser más sencillos y perfectamente ejecutables de forma casi inmediata en los PCs. No obstante, suele seguir un proceso de profundización y crecimiento de la complejidad que puede llevarnos al hecho que comenzamos a percibir que nuestro PC tiene unas limitaciones, y eso por supuesto es una limitación para el desarrollo de nuestra I+D+i.
Evidentemente esta barrera impuesta por los limitados recursos computacionales de nuestro PC es un techo de vigas y cemento bien palpable por los investigadores, pero genera también un sutil techo de cristal. Por supuesto, el investigador será consciente de lo que sus recursos le permiten hacer y no abordará proyectos que lo superen, será consciente de las ideas que puede llevar adelante y las que ha de aparcar y en su caso podría tratar de buscar soluciones para sortear esta barrera. El problema son los proyectos que estamos apartando por inviables de forma subconsciente, esto nos puede dar una falsa percepción sobre nuestras verdaderas posibilidades dado que no vamos a evaluar y menos tratar de llevar a cabo proyectos que no nos estamos planteando.
Esto al lector le puede parecer absurdo o poco probable, o tal vez es que verdaderamente el techo de cristal le es invisible.
Un ejemplo se da en el ajedrez. El jugador sabe o evalúa de forma generalista donde están los puntos de interés de la partida en el tablero y evalúa unos pocos movimientos interesantes de entre todas las combinaciones existentes. La inmensa mayoría de las combinaciones son descartadas de forma automática y no consciente. Esto permite al ajedrecista jugar una buena partida a pesar de apenas explorar combinaciones, pero es también su perdición porque en muchos casos no se evalúan jugadas ganadoras. De hecho es un comentario habitual a posteriori el comentar “no vi esta jugada”, no la evaluó, fue invisible para el jugador (hasta existe el libro “Las jugadas invisibles en ajedrez”).
Este es un ejemplo de como nuestro cerebro toma decisiones lógicas basadas en nuestro conocimiento sin que seamos conscientes de ello, y como en el caso que nos ocupa puede estar creando un techo de cristal al investigador que no siempre es consciente de todos los proyectos que no está llevando a cabo. La cuestión que se plantea en este artículo no es que líneas evalúa el investigador, sino las que habrá descartado inconscientemente.
Profesionalización de la computación
Una de las maneras de evitar este techo de cristal es la profesionalización. No nos cabe duda de que si vamos a comenzar una actividad profesional en la que queremos ser competitivos tendremos que recurrir a las herramientas adecuadas. Así, aunque la mayoría disponemos de un coche particular si para llevar a cabo nuestra actividad profesional necesitamos un vehículo de competición, de carga, de transporte de pasajeros, etc. lo adquirimos y no usamos nuestro vehículo personal, pues aunque en algunos casos podría ser suficiente para llevar a cabo la actividad no resultaría adecuado o competitivo.
En computación no se da este caso y muchos investigadores no recurren a entornos profesionales de cálculo, por decisión propia, por desconocimiento o por lo que podríamos denominar tal vez, falta de cultura en este sentido. Por aclarar esto último creo que a sería muy llamativo que un investigador comprase cristalería del Ikea para su laboratorio, aunque le podría ser suficiente en algunos casos, pero no es tan llamativo usar PCs domésticos para calcular.
En estos casos a la larga pueden verse afectados por el techo de cristal. Todos los años tenemos casos de investigadores que finalmente recurren a nosotros con cálculos que ya les son imposibles y les están produciendo situaciones de penuria, pero que para nuestras máquinas de cálculo profesionales son de pequeño tamaño.
Evidentemente un cluster como el del Servicio de Cálculo de la UPV/EHU también tiene sus limitaciones, pero el salto cualitativo de un PC a un cluster como el nuestro es mayor que el de nuestro cluster a los superordenadores más potentes del mundo. El investigador ya está usando un entorno y metodologías profesionales, la barrera física de los recursos no sólo está mucho más arriba sino que es más permeable y es más fácil encontrar soluciones a los problemas, por lo que no serán descartados inconscientemente tantos problemas científicos porque la metodología de trabajo es totalmente diferente.
|
|
Comentarios