|
|
In the Scientific Computing Service of the UPV/EHU (IZO-SGI) we believe that we can strongly support scientific funding applications for research projects involving High Performance Computing (HPC) due to our service quality and reputation gained over the last 10 years. European computing resources access policy boosts the access to shared computing resources as the ones of the IZO-SGI, in opposition to resources monopolized by individual users or groups.
From this point of view, we have prepared this detailed technical and management report regarding our Service that you might find interesting to include in your funding applications to access High Performance Computing infrastructure. For any questions, requests or clarifications do not hesitate to contact us.
Feel free to copy, summarize or adapt this text to your requirements.
Introduction
The Scientific Computing Service (IZO-SGI) belongs to the UPV/EHU General Research Services (SGIker). The Service provides access to outstanding High Performance Computing (HPC) resources, software and support. It gives service to the entire scientific community of the Basque Country, including researchers from the UPV/EHU (main research institution in the Basque Country), but also to the entire scientific and industrial community. The Service holds, since 2004, an HPC cluster that has regularly been expanded to meet the growing demand of HPC resources by the wide variety of research groups covering all areas of Science (Physics, Chemistry, Engineering, Computer Science, Mathematics, Biology, Geology, Economics, etc).
Infraestructure
An HPC cluster is not standard IT equipment, it is a complex scientific equipment assembled with very specific elements. As that, it requires highly qualified personnel and should be placed in a space designed to guarantee its optimal performance. The HPC cluster of the IZO-SGI has been designed internally to satisfy the needs of a broad spectrum of researchers as a single heterogeneous computing entity. This heterogeneity makes it a flexible and valuable tool nearly for all areas of science, as demonstrated by the wide range of researchers who used it. The resources are summarized below:
- Bianual resources update policy.
- 3728 computational cores with IA64 and x86-64 architectures that allow the execution of standard and massive calculations..
- 6 Nodes with 2 Nvidia GPGPUs each to exploit the programs that use this new technology.
- Nodes with large RAM for jobs with these specific requirements (up to 512 GB of RAM).
- High performance, high capacity and high read/write speed filesystems based on Lustre. 3 different systems with up to 40 TB of storage and 7 GB/s read and write speed.
- Everything interconnected with a high bandwidth and low latency InfiniBand network. The last acquisition with 56 Gb/s Infiniband FDR.
- Management servers under high availability to ensure 24h*365 operation.
- Everything installed in the Data Processing Center (DPC) of the UPV/EHU with a all the elements to ensure optimal performance of the cluster (see next point for details of the DPC).
For a more detailed technical specification visit the computational resources web page of the Service.
The concentration of human and computational resources in the IZO-SGI makes a community and provides to research groups access to a qualitatively and quantitatively superior resources, which result in an increasing scientific productivity. Analogously, the use and amortization of the infrastructure and related secondary costs is extremely efficient and effective.
Data processing Center
The equipment is installed in the DPC of the UPV/EHU newly built in 2006. The DPC has 450 m² and is intended to guarantee the proper and continuous functioning of the computers hosted therein. For that, it is fully equipped with elements that makes possible the 24x7x365 functioning of the cluster:
- Precision air conditioning systems exclusive and direct expansion water softening system. 7 air conditioning units with an aggregate capacity of 208KW, ensuring N+1 redundancy against failure.
- Fire system. Fire detection system using optical and thermal detectors. HI-FOG water mist extinguishing system that preserves the integrity of computer equipment in case of activation.
- Connection to two separate electrical power transformers.
- Double electric branch for IT equipment, each with independent UPS (uninterruptible power supplies) and separate low voltage boxes. It allows redundancy and maintenance without power off of the electrical installation.
- 750 KVA power generator with two days of autonomy without refueling.
- Access control, alarms and security by closed circuit TV.
- User and systems data backup.
- Monitoring, management and control by in-situ operators.
- 5S method to improve the quality.
The facilities are monitored in-situ and remotely with maintenance and periodic revisions in order.The ICT department has a secondary DPC in another building, that keeps duplicate the basic services to prevent operation failures in an event of a major disaster. For example, backups are performed on this DPC to maintain separate data and backups.
Other services
The ICT department maintains the UPV/EHU data network that consists of front-line and last generation technologies. This allows to establish connections with high bandwidth (up to 10Gbps) and a high degree of security, which is essential to work effectively in an infrastructure where all the researches connect remotely. The network has redundant hardware elements and communication lines with diversified duplicate paths and a perimeter firewall, network demilitarized zones, balancers, hardware detection systems of unsafe or potentially dangerous sources, etc. The Internet external connection is done through i2basque, the regional scientific network, which in turn connects to RedIRIS, the Spanish academic and research network.
The ICT department also offers a massive storage system for researchers which is integrable in the IZO-SGI. This storage service is highly secure, there is a mirror in the secondary CPD, and is scalable in capacity and bandwidth to meet current and future requirements.
Personnel
Specific techncal staff
An HPC cluster is a very complex scientific equipment. The specific, particular design and management that requires the IZO-SGI cluster is carried out by two doctors with extensive experience in Scientific Computing. They manage the Service since 2004 and previous experience in HPC obtained during their doctoral formation. Specifically, the two technicians have academic background (PhD) in Chemistry and Physics, two of the scientific areas that make heavier use of HPC, allowing them to offer a service of scientific advice with high added value.
The administrative structure of the SGIker, 12 people, is responsible for administrative tasks such as financial management, management and general administration. Other SGIker units give also internal support such as Quality Service and Innovation, Science metrics and infrastructure.
Non specific personnel
A scientific director with extensive experience, knowledge and vision of HPC in general and in the field of computational chemistry in particular guides the service in making strategic decisions.
The ICT deparment is the largest department of the UPV/EHU in personnel. The staff dedicated to computing tasks far exceeds 150 people. Calculation Service IZO-SGI maintains close contact and cooperation with various areas:
- With the operation area that provides maintenance services, equipment, monitoring, etc. that the IZO-SGI uses.
- With the network area to enable network services, ports, rules, etc. that are required for the proper functioning of hardware and software and allow remote connection of researchers to our clusters.
- With the teaching support area supports us in managing the Pendulum GRID that uses teaching computer rooms for computing at nights. Also for the installation of software that manages the IZO-SGI that is used for teaching in addition to research.
- With the area of customer service, which solves problems in the searchers PCs. They support and solved on-site more efficiently problems such as installing software on their personal computers.
The integration of the IZO-SGI into the UPV/EHU provides also all the administrative and technical services of the UPV/EHU structure.
Quality and evaluation policy
SGIker is committed with the quality and have defined quality policy that serves as a frame of reference in setting goals, targets and implement quality programs. The quality of services offered is the cornerstone of the SGIker. Proof of this commitment is the existence of Quality and Innovation Unit that focuses its efforts on the implementation, maintenance and continuous improvement of a System of Quality Management based on international standards.
The Quality and Innovation Unit of the General Research Services SGIker carries out, every year, among researchers an user satisfaction independent survey. The IZO-SGI has an 9.6 average over the last five years.
El Servicio General de Informática Aplicada a la Investigación (Cálculo Científico) ha renovado la licencia corporativa para la UPV/EHU del programa de dinámica de fluidos (CFD) STARCCM+ y el programa de HEEDS que automatiza el proceso de optimización de parámetros en diseños, para el año 2017.
Estas licencias pueden usarse en los clusters de cálculo del Servicio de Cálculo Científico de la UPV/EHU. También pueden solicitarse licencias personales para uso en los ordenadores de los investigadores, para ello es necesario realizar una solicitud a los técnicos del Servicio de Cálculo Científico.
Características de la licencia
La licencia será válida hasta Febrero del 2017 y permite el uso de todos los procesadores del ordenador. Se puede usar en ordenadores corporativos de la UPV/EHU o a través de VPN.
Se dispone de licencia de docencia que permite la instalación de STARCCM+ en las aulas de docencia de la UPV/EHU para impartir cursos y asignaturas.
Tarifa STARCCM+
El uso de STARCCM+ en aulas para docencia de cursos y asignaturas es gratuito.
El uso de STARCCM+ en el cluster de cálculo Arina de la UPV/EHU es gratuito y solo se factura el uso de horas de cálculo según la tarifa estándar del Servicio.
Las tarifas que se aplicarán para la instalación de licencias en los ordenadores personales de los investigadores se detalla a continuación.
- Licencias de docencia y pruebas.
Para un PC y menos de 250 horas. Se pueden solicitar licencias gratuitas para probar el programa, realizar tareas relacionadas con la docencia o proyectos de fin de máster. Estas licencias estarán restringidas a un máximo de 250 horas de uso.
- Licencias de investigación en PCs
Las licencias destinadas a su instalación en ordenadores corporativos personales cuyo uso va a ser de más de 250 horas, y por tanto se consideran de investigación, se facturará a 250 € por equipo.
- Licencias de investigación en estaciones de trabajo y servidores.
Las licencias destinadas a su instalación en estaciones de trabajo y servidores (procesadores xeon o similares) tendrá un coste de 50 € por core.
 Más información Más información
- Página web CD-Adapco, proveedor del software.
Para poder usar HEEDS póngase en contacto con los técnicos.
El viernes 16 de Septiembre de 2016 de 12:00 a 12:30 se realizará una reunión informatíva del curso
Fundamentos técnicos de CFD para energía eólica
impartido por profesorado de la UPV/EHU y del CENER (Centro Nacional de Energias Renovables). Está dirigido a:
- Estudiantes de último curso de grado
- Estudiantes en fase de realización del trabajo fin de grado
- Egresados del curso actual o anteriores
- Trabajadores de empresas
Lugar:
Sala de Reuniones 1
Escuela de Ingeniería de Vitoria-Gasteiz
Nieves Cano 12, 01006 Vitoria-Gasteiz
Más información
Unai Fernández Gamiz
Departamento de Ingeniería Nuclear y Mecánica de Fluidos
e-mail: unai.fernandez@ehu.eus
Teléfono: 94 501 4066
El superodenador Sunway TaihuLight es el nuevo superordenador más potente del mundo. Este superordenador chino ha relegado al segundo lugar de la lista de supercomputadoras más potentes del mundo top500.org al también chino Tianhe-2, que ha permanecido 6 listas consecutivas (se actualiza semestralmente) como la supercomputadora más potente del mundo
Sunway TaihuLight tiene un rendimiento teórico de 125 PetaFLOPS y un rendimiento real de 93 PetaFLOPS con el benchmark HPL (High Performance Linpack) lo que representa una eficiencia del 74%. Con esto casi triplica el rendimiento de su antecesor el Tianhe-2 (34 PetaFLOPS y una eficiencia del 62%) con además una eficiencia superior.
 Uno de los hitos más importantes de Sunway TaihuLigth es que está construido tecnología 100% china, entre ellas el procesador el SW26010, con lo que consigue la independencia tecnológica de EE.UU. SunWay TaihuLight no usa coprocesadores sino 40.960 nodos, con 4 procesadores cada nodo, con 64 cores de cómputo más otro de gestión que también participa del cálculo para un total de más de 10,5 millones de cores. No obstante, Sunway TaihuLight a causa de su acceso a memoria y su red de comunicación tiene un rendimiento más pobre en el bechmark más actual HPCG (High Performance Conjutate Gradients), donde incluso el Tianhe-2 lo supera, lo que puede suponer que no sea tan eficaz corriendo un espectro más amplio de aplicaciones. No obstante, si hay software que se ha desarrollado paralelamente al proyecto del hardware y que corre muy eficientemente en Sunway TaihuLigth. Uno de los hitos más importantes de Sunway TaihuLigth es que está construido tecnología 100% china, entre ellas el procesador el SW26010, con lo que consigue la independencia tecnológica de EE.UU. SunWay TaihuLight no usa coprocesadores sino 40.960 nodos, con 4 procesadores cada nodo, con 64 cores de cómputo más otro de gestión que también participa del cálculo para un total de más de 10,5 millones de cores. No obstante, Sunway TaihuLight a causa de su acceso a memoria y su red de comunicación tiene un rendimiento más pobre en el bechmark más actual HPCG (High Performance Conjutate Gradients), donde incluso el Tianhe-2 lo supera, lo que puede suponer que no sea tan eficaz corriendo un espectro más amplio de aplicaciones. No obstante, si hay software que se ha desarrollado paralelamente al proyecto del hardware y que corre muy eficientemente en Sunway TaihuLigth.
China desbanca a EE.UU en el Top500
En la lista de Junio de 2016 es la primera vez en la historia del Top500 que EE.UU no es el país con el mayor número de sistemas instalados. En esta lista dispone de 165 sistemas que supera China con 167 supercomputadoras. China también es el país que más rendimiento aglutina en toda la lista, gracias especialmente a los dos superordenadores que tiene como números 1 y 2 de la lista.
Es este video PayPal nos muestra como necesita hacer uso de HPC para gestionar todas las pagos online y transacciones que realiza y gestionar la información de todos sus usuarios.
https://youtu.be/rBLL1uyP3ic?list=PLyZk_jpQ4X_ofn678tWR0ROTDDy9ck3OB
Bideo honetan PayPalek erakusten digu nola erabiltzen duen HPCa egunero egin kudeatu behar dituen ordainketentzako, transakzio ekonomikoentzat eta erabiltzailei buruzko inforamazioa.
https://youtu.be/rBLL1uyP3ic?list=PLyZk_jpQ4X_ofn678tWR0ROTDDy9ck3OB
Introduction
Barcelona Computing Week 2014, July 11-15, at BSC/UPC, Barcelona.
 The BSC/UPC has been awared by Nvidia as GPU Center of Excellence. The Programming and tUning Massively Parallel Systems Summer School (PUMPS) offers researchers and graduate students a unique opportunity to enrich their skills with cutting-edge technique and hands-on experience in developing applications for many-core processors with massively parallel computing resources like GPU accelerators. The BSC/UPC has been awared by Nvidia as GPU Center of Excellence. The Programming and tUning Massively Parallel Systems Summer School (PUMPS) offers researchers and graduate students a unique opportunity to enrich their skills with cutting-edge technique and hands-on experience in developing applications for many-core processors with massively parallel computing resources like GPU accelerators.
Participants will have access to a multi-node cluster of GPUs, and will learn to program and optimize applications in languages such as CUDA and OmpSs. Teaching assistants will be available to help with assignments.
Important information
- Applications due: May 31
- Notification of acceptance: June 10
- Summer school dates: July 11-15, 2014
- Location: Barcelona Supercomputing Center / Computer Architecture Dept. at Universitat Politecnica de Catalunya, Barcelona, Spain. Room TDB.
Lecturers
- Distinguished Lectures:
- Wen-mei Hwu, University of Illinois at Urbana-Champaign.
- David Kirk, NVIDIA Fellow, former Chief Scientist, NVIDIA Corporation.
- Invited Lecturer: Juan Gómez Luna (Universidad de Cordoba).
- BSC/UPC Lecturers:
- Xavier Martorell
- Xabier Teruel
- .Teaching Assistants:
- Abdul Dakkak, Carl Pearson, Simon Garcia de Gonzalo, Marc Jorda, Pau Farre, Javier Bueno, Aimar Rodriguez.
The list of topics
- CUDA Algorithmic Optimization Strategies.
- Dealing with Sparse and Dynamic data.
- Efficiency in Large Data Traversal.
- Reducing Output Interference.
- Controlling Load Imbalance and Divergence.
- Acceleration of Collective Operations.
- Dynamic Parallelism and HyperQ.
- Debugging and Profiling CUDA Code.
- Multi-GPU Execution.
- Architecture Trends and Implications
- FORTRAN Interoperability and CUDA Libraries.
- Introduction to OmpSs and to the Paraver analysis tool.
- OmpSs: Leveraging GPU/CUDA Programming.
- Hands-on Labs: CUDA Optimizations on Scientific Codes. OmpSs Programming and Tuning.
More information
Autor: Luis Fer Coca, alumno del centro IEFPS Elorrieta-Erreka Mari en prácticas en el IZO-SGI.
La GPU o Unidad de Procesamiento de Gráficos es un coprocesador dedicado al procesamiento de gráficos, que sirve para aligerar la carga de trabajo del procesador en el procesamiento de los gráficos a mostrar en pantalla.
Pero en 2007 surgió el cálculo acelerado en la GPU, que lo podemos definir como el uso de una unidad de procesamiento gráfico en combinación con la CPU para acelerar los análisis y cálculos de aplicaciones de investigación, empresa, consumo, ingeniería,etc. Desde entonces, las GPU aceleradoras han pasado a instalarse en centros de datos de laboratorios gubernamentales, universidades, grandes compañías y PYMEs de todo el mundo.
El uso y mercado de las GPU, ya no es sólo como tarjetas gráficas para disfrutar de los últimos videojuegos con la mejor calidad, si no que también en el sector del HPC con ordenadores de alto rendimiento que ejecutan miles de millones de operaciones, y donde las GPUs hacen determinadas operaciones más rápidas que una CPU del mismo rango.
La GPU frente al procesador
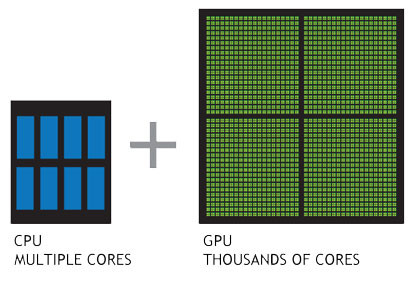 Una forma sencilla de entender la diferencia entre el procesador y la GPU es comparar la forma en que procesan las tareas. Un procesador está formado por varios núcleos de propósito general, mientras que una GPU consta de millares de núcleos más pequeños y eficientes, diseñados para ejecutar múltiples operaciones matemáticas simultáneamente. Una forma sencilla de entender la diferencia entre el procesador y la GPU es comparar la forma en que procesan las tareas. Un procesador está formado por varios núcleos de propósito general, mientras que una GPU consta de millares de núcleos más pequeños y eficientes, diseñados para ejecutar múltiples operaciones matemáticas simultáneamente.
Las GPUs en el Top500
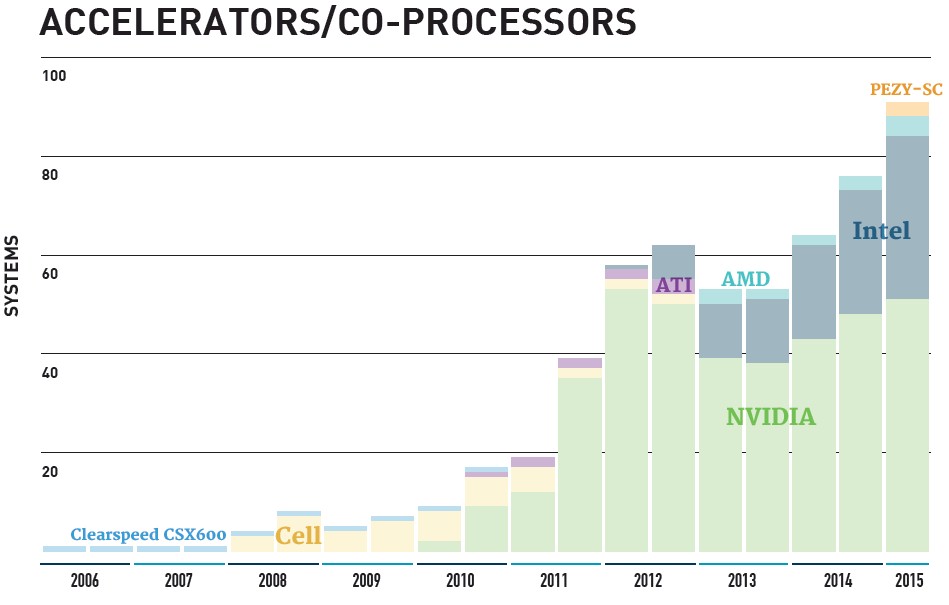
Como podemos observar en la gráfica del Top500, entre los sistemas con coprocesadores, las GPU aceleradoras de NVIDIA y AMD dominan actualmente el Top500, sobre los Intel Phi y el nuevo acelerador del fabricante de chips japoneses PEZY COMPUTING.Asímismo observamos el crecimiento que este tipo de tecnologías están teniendo en el mundo del HPC.
Evolución de las GPU Nvidia
Las claves que han hecho la plataforma de aceleración computacional de NVIDIA las más popular para cálculo científico es que combinan las GPUs aceleradoras, el modelo de procesamiento paralelo CUDA, un amplio ecosistema de desarrolladores, proveedores de software y fabricantes de sistemas para HPC y el haber sido una de las pioneras.
Recientemente, NVDIA presentó la nueva Tesla P100 y es oficialmente la GPU más potente del mercado, orientada al sector de los HPC, forma parte de la nueva generación de chips Pascal, que sucede a la generación Maxwell. Está basado en el nuevo proceso de fabricación FinFET de 16 nm, lo que ha permitido multiplicar por dos la densidad de transistores, usando un 70% menos de energía al mismo tiempo. Es una GPU más potente, pero también más eficiente.
En la tabla se observa evolución de algunas GPUs ejemplo de Nvidia.
| Arquitectura |
Fermi |
Kepler |
Pascal |
| GPU |
M2050 |
K20 |
K80 |
P100 |
| Procesadores |
448 |
2496 |
4992 |
3584 |
| Velocidad (MHz) |
1150 |
706 |
562 |
1328 |
| RAM (GB) |
3 |
5 |
24 |
16 |
| Rendimiento en precisión simple |
1.03 TFLOPS |
3.52 TFLOPS |
8.74 TFLOPS |
10.6 TFLOPS |
| Rendimiento en doble precisión |
515 GFLOPS |
1.17 TFLOPS |
2.91 TFLOPS |
5.3 TFLOPS |
| Número de transistores (millones) |
3.1 |
7.1 |
14.2 |
15.3 |
| Consumo eléctrico |
225W |
225W |
300W |
300W |
GPUs Nvidia en el Servicio de Cálculo
El Servicio de Cálculo de la UPV/EHU ha ido adquiriendo esta tecnología desde 2010 para ofrecer un pequeño entorno de producción y test en este campo a los investigadores, actualmente tiene 4 GPUs Fermi C2050, 4 Fermi C2070 y dos Kepler K20. Igualmente está prevista la adquisición de GPUs Kepler k80.
Conclusión
Las tecnologías de coprocesamiento, entre ellas las GPUs, siguen en continuo desarrollo permitiendo el progreso del cálculo científico y preservando la posición del mismo como una herramienta muy útil para la investigación e innovación en infinidad de campos.
Referencias
http://www.nvidia.es/object/tesla-high-performance-computing-es.html
http://wccftech.com/nvidia-pascal-gpu-gtc-2016/
http://www.omicrono.com/2016/04/nvidia-tesla-100/
http://www.almatech.es/nvidia-incorpora-gpu-a-la-arquitectura-kepler/
El Servicio General de Informática Aplicada a la Investigación (Cálculo Científico) ha renovado la licencia corporativa para la UPV/EHU del programa de dinámica de fluidos (CFD) STARCCM+ para el año 2016.
Estas licencias pueden usarse en los clusters de cálculo del Servicio de Cálculo Científico de la UPV/EHU. También pueden solicitarse licencias personales para uso en los ordenadores de los investigadores, para ello es necesario realizar una solicitud a los técnicos del Servicio de Cálculo Científico.
Características de la licencia
La licencia será válida hasta Febrero del 2017 y permite el uso de todos los procesadores del ordenador. Se puede usar en ordenadores corporativos de la UPV/EHU o a través de VPN.
Se dispone de licencia de docencia que permite la instalación de STARCCM+ en las aulas de docencia de la UPV/EHU para impartir cursos y asignaturas.
Tarifa
El uso de STARCCM+ en aulas para docencia de cursos y asignaturas es gratuito.
El uso de STARCCM+ en el cluster de cálculo Arina de la UPV/EHU es gratuito y solo se factura el uso de horas de cálculo según la tarifa estándar del Servicio.
Las tarifas que se aplicarán para la instalación de licencias en los ordenadores personales de los investigadores se detalla a continuación.
- Licencias de docencia y pruebas.
Para un PC y menos de 250 horas. Se pueden solicitar licencias gratuitas para probar el programa, realizar tareas relacionadas con la docencia o proyectos de fin de máster. Estas licencias estarán restringidas a un máximo de 250 horas de uso.
- Licencias de investigación en PCs
Las licencias destinadas a su instalación en ordenadores corporativos personales cuyo uso va a ser de más de 250 horas, y por tanto se consideran de investigación, se facturará a 140 € por equipo.
Se pueden solicitar acceso a equipos por VPN. Los recursos a traveś de VPN son muy limitados, por ello la licencia se renovará trimestralmente con un costo adicional de 35 € por licencia y trimestre.
- Licencias de investigación en estaciones de trabajo y servidores.
Las licencias destinadas a su instalación en estaciones de trabajo y servidores (procesadores xeon o similares) tendrá un coste de 45 € por core.
Más información
- Página web CD-Adapco, proveedor del software.
.
Red Hat Enterprise Linux Server 6.4 has already a quite old OS, and it is not possible to install the precompiled tensorflow packages with pip and so on. So we had to compile it.
The instructions we follow are based on this document:
https://www.tensorflow.org/versions/r0.7/get_started/os_setup.html#installation-for-linux
We want to install it to be run on GPUs, so first we need to register in nvidia
https://developer.nvidia.com/cudnn
to install the cuDNN libraries. Download and copy the include and libraries to the corresponding cuda version directories.
In order to compile tensorflow from source, we first need to compile the bazel compiler.
1.- Installing Bazel
The first problem is that the gcc/g++ compiler in RHELS 6.4 is old, 4.4.7, and at least 4.8 is required. We did install RH devtoolset-3 which provides 4.9.2 version of gcc/g++. We also need Java JDK 8 or later.
Now, we can download bazel:
git clone https://github.com/bazelbuild/bazel.git
And we set up our environment to compile bazel:
export JAVA_HOME=/software/jdk1.8.0_20
export PATH=/opt/rh/devtoolset-3/root/usr/bin:/software/anaconda2/bin:/software/jdk1.8.0_20/bin:$PATH
export LD_LIBRARY_PATH=/opt/rh/devtoolset-3/root/usr/lib64:/opt/rh/devtoolset-3/root/usr/lib:/software/anaconda2/lib64:/software/anaconda2/lib:$LD_LIBRARY_PATH
Then, we have to modify the bazel/tools/cpp/CROSSTOOL file to choose the commands from devtoolset-3 instead of the default ones, in the toolchain_identifier: “local_linux”
toolchain {
abi_version: “local”
abi_libc_version: “local”
builtin_sysroot: “”
compiler: “compiler”
host_system_name: “local”
needsPic: true
supports_gold_linker: false
supports_incremental_linker: false
supports_fission: false
supports_interface_shared_objects: false
supports_normalizing_ar: false
supports_start_end_lib: false
supports_thin_archives: false
target_libc: “local”
target_cpu: “local”
target_system_name: “local”
toolchain_identifier: “local_linux”
tool_path { name: “ar” path: “/opt/rh/devtoolset-3/root/usr/bin/ar” }
tool_path { name: “compat-ld” path: “/opt/rh/devtoolset-3/root/usr/bin/ld” }
tool_path { name: “cpp” path: “/opt/rh/devtoolset-3/root/usr/bin/cpp” }
tool_path { name: “dwp” path: “/opt/rh/devtoolset-3/root/usr/bin/dwp” }
tool_path { name: “gcc” path: “/opt/rh/devtoolset-3/root/usr/bin/gcc” }
cxx_flag: “-std=c++0x”
linker_flag: “-lstdc++”
linker_flag: “-B/opt/rh/devtoolset-3/root/usr/bin/”
# TODO(bazel-team): In theory, the path here ought to exactly match the path
# used by gcc. That works because bazel currently doesn’t track files at
# absolute locations and has no remote execution, yet. However, this will need
# to be fixed, maybe with auto-detection?
cxx_builtin_include_directory: “/opt/rh/devtoolset-3/root/usr/lib/gcc/”
cxx_builtin_include_directory: “/opt/rh/devtoolset-3/root/usr/include”
tool_path { name: “gcov” path: “/opt/rh/devtoolset-3/root/usr/bin/gcov” }
# C(++) compiles invoke the compiler (as that is the one knowing where
# to find libraries), but we provide LD so other rules can invoke the linker.
tool_path { name: “ld” path: “/opt/rh/devtoolset-3/root/usr/bin/ld” }
tool_path { name: “nm” path: “/opt/rh/devtoolset-3/root/usr/bin/nm” }
tool_path { name: “objcopy” path: “/opt/rh/devtoolset-3/root/usr/bin/objcopy” }
objcopy_embed_flag: “-I”
objcopy_embed_flag: “binary”
tool_path { name: “objdump” path: “/opt/rh/devtoolset-3/root/usr/bin/objdump” }
tool_path { name: “strip” path: “/opt/rh/devtoolset-3/root/usr/bin/strip” }
compilation_mode_flags {
mode: DBG
# Enable debug symbols.
compiler_flag: “-g”
}
compilation_mode_flags {
mode: OPT
# No debug symbols.
# Maybe we should enable https://gcc.gnu.org/wiki/DebugFission for opt or even generally?
# However, that can’t happen here, as it requires special handling in Bazel.
compiler_flag: “-g0”
# Conservative choice for -O
# -O3 can increase binary size and even slow down the resulting binaries.
# Profile first and / or use FDO if you need better performance than this.
compiler_flag: “-O2”
# Disable assertions
compiler_flag: “-DNDEBUG”
# Removal of unused code and data at link time (can this increase binary size in some cases?).
compiler_flag: “-ffunction-sections”
compiler_flag: “-fdata-sections”
}
linking_mode_flags { mode: DYNAMIC }
}
Now, we can compile it with the command:
./compile.sh
It will create a binary bazel, that we will use now to compile tensorflow.
2.- Tensorflow
Download Tensorflow
git clone –recurse-submodules https://github.com/tensorflow/tensorflow
We define the environment to compile tensorflow with the devtools-3 and with cuda
export JAVA_HOME=/software/jdk1.8.0_20
export PATH=/software/jdk1.8.0_20/bin:/opt/rh/devtoolset-3/root/usr/bin:/software/anaconda2/bin:/software/cuda-7.5.18/bin:$PATH
export LD_LIBRARY_PATH=/opt/rh/devtoolset-3/root/usr/lib64:/opt/rh/devtoolset-3/root/usr/lib:/software/cuda-7.5.18/lib64:/software/anaconda2/lib64:/software/anaconda2/lib:$LD_LIBRARY_PATH
We run configure in tensorflow to setup our cuda envirnment:
cd tensorflow
Fix the google/protobuf/BUILD file changing:
LINK_OPTS = [“-lpthread”]
to
LINK_OPTS = [“-lpthread”,”-lrt”,”-lm”]
and configure it
./configure
Please specify the location of python. [Default is /software/anaconda2/bin/python]:
Do you wish to build TensorFlow with GPU support? [y/N] y
GPU support will be enabled for TensorFlow
Please specify the Cuda SDK version you want to use, e.g. 7.0. [Leave empty to use system default]: 7.5
Please specify the location where CUDA 7.5 toolkit is installed. Refer to README.md for more details. [Default is /usr/local/cuda]: /software/cuda-7.5.18
Please specify the Cudnn version you want to use. [Leave empty to use system default]:
Please specify the location where cuDNN library is installed. Refer to README.md for more details. [Default is /software/cuda-7.5.18]:
Please specify a list of comma-separated Cuda compute capabilities you want to build with.
You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus.
Please note that each additional compute capability significantly increases your build time and binary size.
[Default is: “3.5,5.2”]: 3.5
As we did in bazel, we need to fix the CROSSTOOL file third_party/gpus/crosstool/CROSSTOOL:
toolchain {
abi_version: “local”
abi_libc_version: “local”
builtin_sysroot: “”
compiler: “compiler”
host_system_name: “local”
needsPic: true
supports_gold_linker: false
supports_incremental_linker: false
supports_fission: false
supports_interface_shared_objects: false
supports_normalizing_ar: false
supports_start_end_lib: false
supports_thin_archives: false
target_libc: “local”
target_cpu: “local”
target_system_name: “local”
toolchain_identifier: “local_linux”
tool_path { name: “ar” path: “/opt/rh/devtoolset-3/root/usr/bin/ar” }
tool_path { name: “compat-ld” path: “/opt/rh/devtoolset-3/root/usr/bin/ld” }
tool_path { name: “cpp” path: “/opt/rh/devtoolset-3/root/usr/bin/cpp” }
tool_path { name: “dwp” path: “/opt/rh/devtoolset-3/root/usr/bin/dwp” }
# As part of the TensorFlow release, we place some cuda-related compilation
# files in third_party/gpus/crosstool/clang/bin, and this relative
# path, combined with the rest of our Bazel configuration causes our
# compilation to use those files.
tool_path { name: “gcc” path: “clang/bin/crosstool_wrapper_driver_is_not_gcc” }
# Use “-std=c++11” for nvcc. For consistency, force both the host compiler
# and the device compiler to use “-std=c++11”.
cxx_flag: “-std=c++11”
linker_flag: “-lstdc++”
linker_flag: “-B/opt/rh/devtoolset-3/root/usr/bin/”
# TODO(bazel-team): In theory, the path here ought to exactly match the path
# used by gcc. That works because bazel currently doesn’t track files at
# absolute locations and has no remote execution, yet. However, this will need
# to be fixed, maybe with auto-detection?
cxx_builtin_include_directory: “/opt/rh/devtoolset-3/root/usr/lib/gcc/”
cxx_builtin_include_directory: “/usr/local/include”
cxx_builtin_include_directory: “/usr/include”
cxx_builtin_include_directory: “/opt/rh/devtoolset-3/root/usr/include”
tool_path { name: “gcov” path: “/opt/rh/devtoolset-3/root/usr/bin/gcov” }
# C(++) compiles invoke the compiler (as that is the one knowing where
# to find libraries), but we provide LD so other rules can invoke the linker.
tool_path { name: “ld” path: “/opt/rh/devtoolset-3/root/usr/bin/ld” }
tool_path { name: “nm” path: “/opt/rh/devtoolset-3/root/usr/bin/nm” }
tool_path { name: “objcopy” path: “/opt/rh/devtoolset-3/root/usr/bin/objcopy” }
objcopy_embed_flag: “-I”
objcopy_embed_flag: “binary”
tool_path { name: “objdump” path: “/opt/rh/devtoolset-3/root/usr/bin/objdump” }
tool_path { name: “strip” path: “/opt/rh/devtoolset-3/root/usr/bin/strip” }
# Anticipated future default.
unfiltered_cxx_flag: “-no-canonical-prefixes”
# Make C++ compilation deterministic. Use linkstamping instead of these
# compiler symbols.
unfiltered_cxx_flag: “-Wno-builtin-macro-redefined”
unfiltered_cxx_flag: “-D__DATE__=\”redacted\””
unfiltered_cxx_flag: “-D__TIMESTAMP__=\”redacted\””
unfiltered_cxx_flag: “-D__TIME__=\”redacted\””
# Security hardening on by default.
# Conservative choice; -D_FORTIFY_SOURCE=2 may be unsafe in some cases.
# We need to undef it before redefining it as some distributions now have
# it enabled by default.
compiler_flag: “-U_FORTIFY_SOURCE”
compiler_flag: “-D_FORTIFY_SOURCE=1”
compiler_flag: “-fstack-protector”
compiler_flag: “-fPIE”
linker_flag: “-pie”
linker_flag: “-Wl,-z,relro,-z,now”
# Enable coloring even if there’s no attached terminal. Bazel removes the
# escape sequences if –nocolor is specified. This isn’t supported by gcc
# on Ubuntu 14.04.
# compiler_flag: “-fcolor-diagnostics”
# All warnings are enabled. Maybe enable -Werror as well?
compiler_flag: “-Wall”
# Enable a few more warnings that aren’t part of -Wall.
compiler_flag: “-Wunused-but-set-parameter”
# But disable some that are problematic.
compiler_flag: “-Wno-free-nonheap-object” # has false positives
# Keep stack frames for debugging, even in opt mode.
compiler_flag: “-fno-omit-frame-pointer”
# Anticipated future default.
linker_flag: “-no-canonical-prefixes”
unfiltered_cxx_flag: “-fno-canonical-system-headers”
# Have gcc return the exit code from ld.
linker_flag: “-pass-exit-codes”
# Stamp the binary with a unique identifier.
linker_flag: “-Wl,–build-id=md5”
linker_flag: “-Wl,–hash-style=gnu”
# Gold linker only? Can we enable this by default?
# linker_flag: “-Wl,–warn-execstack”
# linker_flag: “-Wl,–detect-odr-violations”
compilation_mode_flags {
mode: DBG
# Enable debug symbols.
compiler_flag: “-g”
}
Similarly, we also need to fix /third_party/gpus/crosstool/clang/bin/crosstool_wrapper_driver_is_not_gcc to choose the devtools-3 tools.
Now, we will build a build_pip_package:
bazel build -c opt –config=cuda –genrule_strategy=standalone –verbose_failures //tensorflow/tools/pip_package:build_pip_package
I got an error, "ImportError: No module named argparse" so I had to change also the first line of /third_party/gpus/crosstool/clang/bin/crosstool_wrapper_driver_is_not_gcc to:
#!/usr/bin/env /software/anaconda2/bin/python2
Then, we create the python wheel package:
tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
In my case, I had to run
/root/.cache/bazel/_bazel_root/28150a65056607dabfb056aa305868ed/tensorflow/bazel-out/local_linux-opt/bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
And finally we can install it using pip:
bazel build -c opt –config=cuda –genrule_strategy=standalone //tensorflow/cc:tutorials_example_trainer
pip install /tmp/tensorflow_pkg/tensorflow-0.7.1-py2-none-any.whl
We also tried to compile the tutorials_example_trainer as shown in the tensorflow webpage:
bazel build -c opt –config=cuda –genrule_strategy=standalone //tensorflow/cc:tutorials_example_trainer
And successfully run the test:
tutorials_example_trainer –use_gpu
We would like to thank Kike from IXA-taldea for sharing with us his guide to compile tensorflow in CPUs.
|
|
Comentarios