|
|
Programming and tuning Massively Parallel Systems Summer School (PUMPS)
This fourth edition offers researchers and graduate students a unique opportunity to improve their skills with cutting-edge techniques and hands-on experience in developing and tuning applications for many-core processors with massively parallel computing resources like GPU accelerators. Participants will have access to a multi-node cluster of GPUs, and will learn to program and optimize applications in languages such as CUDA and OmpSs. Teaching Assistants will be available to help with Hands-on Labs assignments. The summer school is oriented towards advanced programming and optimizations, and thus previous experience in basic GPGPU programming will be considered in the selection process.
Important information
| When: |
July 8-12 |
| Where: |
Barcelona Supercomputing Center (BSC) / Computer Architecture Dept. at Universitat Politecnica de Catalunya, Barcelona (Spain)
|
| Application due: |
May 17 |
| Notification of acceptance: |
May 31 |
Lecturers
- Wen-mei Hwu, University of Illinois at Urbana-Champaign.
- David Kirk, NVIDIA Fellow, former Chief Scientist, NVIDIA Corporation.
- Isaac Gelado, Rosa Badia, Xavier Martorell, Nacho Navarro (BSC and UPC).
Some of the topics that will be covered during the course are
- CUDA Algorithmic Optimization Strategies.
- Dealing with Sparse and Dynamic data.
- Efficiency in Large Data Traversal.
- Reducing Output Interference.
- Controlling Load Imbalance and Divergence.
- Debugging and Profiling CUDA Code.
- GMAC Runtime.
- Multi-GPU Execution.
- Introduction to OmpSs.
- OmpSs: Leveraging GPU/CUDA Programming.
- Hands-on Labs: CUDA Optimizations and OmpSs Programming.
More information
Complete information, program and registration: http://bcw.ac.upc.edu/PUMPS2013
Contact: bcw2013@bcw.ac.upc.edu
El Servicio Cálculo Científico (IZO-SGI) de la UPV/EHU ha adquirido para los investigadores de la UPV/EHU licencia corporativa del programa de simulación computacional de mecánica de fluidos (CFD) STAR-CCM+. El uso del mismo en ordenadores y servidores ajenos a los del IZO-SGI se debe solicitar a los técnicos del Servicio y se facturará anualmente según los siguientes criterios:
- Licencia para PCs de 4 o menos cores: 100 €. No se facturará si se solicita para uso esporadico y este es menor a 100 horas.
- El acceso de la licencia a servidores se hará en función del número de cores totales de los servidores solicitados de alta según la siguiente tabla:
| 1-16 cores |
35 € por core |
| 17-40 cores |
Tramo anterior más 25 € por core extra. |
| A partir de 40 cores |
Tramo anterior más 15 € por core extra. |
- Existen licencias para docencia cuyas condiciones se pueden consultar en este link.
Sobre Starccm+
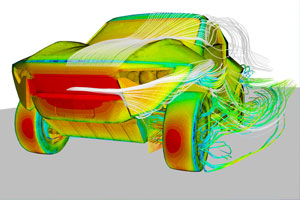 Starccm+ provides the world’s most comprehensive engineering simulation inside a single integrated package. Much more than just a CFD solver, STAR-CCM+ is an entire engineering process for solving problems involving flow (of fluids or solids), heat transfer and stress. Starccm+ provides the world’s most comprehensive engineering simulation inside a single integrated package. Much more than just a CFD solver, STAR-CCM+ is an entire engineering process for solving problems involving flow (of fluids or solids), heat transfer and stress.
El Servicio General de Informática Aplicada a la Investigación (Cálculo Científico) dispone de licencias para docencia del programa de CFD StarCCM+ para el año 2013 para impartir asignaturas de la UPV/EHU y proyectos fin de carrera. También se disponen de licencias para Inversigación (ver quí).
Es necesario que el docente haga una solicitud a los técnicos.
- Licencias de docencia
Se deberá de remitir la siguiente información a los técnicos.
- Número de alumnos.
- Número de licencias (ordenadores en el aula).
- Periodo y horario de las clases.
- Nombre de la asignatura.
- Proyectos fin de carrera
Se deberá de remitir la siguiente información a los técnicos.
- Título del proyecto.
- Periodo de realización.
- Si hubiese colaboración con alguna empresa nombre de la misma.
- Tras su finalización se deberá de remitir la memoria del proyecto a CD-Adapco.
Sobre Starccm+
Starccm+ provides the world’s most comprehensive engineering simulation inside a single integrated package. Much more than just a CFD solver, STAR-CCM+ is an entire engineering process for solving problems involving flow (of fluids or solids), heat transfer and stress.

El 23 de Abril se celebrará en la Escuela de Ingeniería de Gasteiz el workshop “Applied fluid mechanics” organizado por el “Green Energy Taldea“. Es necesario registrarse.
Programa
- 9:00-9:15 Opening by UPV/EHU-Green Energy Taldea.
- 9:15-10:00 Passive and active control strategies implemented in wind energy research at DTU.
C. M. Velte. Technical University of Denmark-DTU.
- 10:00-10:45 Large Scale Simulations of Turbulent Flows for Industrial Applications
L. Remaki. BCAM-Basque Center for Applied Mathematics, Bilbao.
- 11:15-12:00 Models of Wind turbine Wakes.
A. Crespo. UPM-Technical University of Madrid.
- 12:00-12:45 Control Algorithms for Horizontal Axis Wind Turbines.
E. Zulueta. Automatic and control department. University of the Basque Country.
- 12:45-13:30 IZO-SGI SGIker, Scientific Computing at the UPV/EHU.
J. M. Mercero. IZO-SGI SGIker, University of the Basque Country.
Más información
Página web del evento, aquí.
 Asistentes a la Jornada en Donostia. El pasado 8 de Marzo se celebró la “Jornada de Supercomputación en Euskadi” en Donostia, la cual se difundió por videoconferencia a todos los campus de la UPV/EHU. Los que estéis interesados podéis bajaros las presentaciones que colgamos y para los que no estuvisteis, Txoni Matxain, uno de los ponentes, resumió la jornada que podéis encontrar en el siguiente link http://goo.gl/c8xiD (Euskeraz).
Presentaciones de la jornada:
– Recursos HPC del IZO-SGI SGIKer de la UPV/EHU
José M. Mercero (IZO-SGI SGIKer UPV/EHU)
– Presentación de i2basque
Josu Aramberri, Coordinador de i2basque
Rosario Sánchez Ojeda, Responsable HPC de i2basque
– Proyecto Biosoft: ejemplo de computación ciudadana mediante la plaforma Ibercivis
Javier Aldazabal (Centro de Estudios e Investigaciones Técnicas de Gipuzkoa-CEIT)
Iñigo Aldazabal (Centro de Física de Materiales (CSIC-UPV/EHU))
– Recursos de supercomputación a través de BSC-CNS, RES y PRACE
Montserrat González, (BSC-CNS)
– Presentación de un proyecto con acceso a RES. Experiencia de usuario.
Txoni Matxain (UPV/EHU)
– Presentación de proyecto con acceso a PRACE. Experiencia de usuario.
Angel Rubio (UPV/EHU)
El próximo 8 de Marzo el BSC-CNS, como coordinador de la RES (Red Española de Supercomputación), celebrará una jornada de supercomputación para informar sobre los actuales recursos disponibles y los métodos de solicitud de acceso a éstos en la RES y en PRACE (Partnership for Advanced Computing in Europe) durante 2013.
El Servico de Cálculo Científico (IZO-SGI) de la UPV/EHU realizará una pequeña presentación.
El evento se celebrará en el salón de actos del Edificio Korta de la UPV/EHU en San Sebastián y se podrá seguir por videoconferencia en:
- Alava. Aulario Las Nieves, Calle Nieves Cano 33, 01006 Vitoria-Gasteiz.
- Bizkaia, ET Superior de Ingenieros, Alameda Urquijo s/n. 48013 – Bilbao
- Bizkaia, Campus de Leioa, Facultad de Ciencia y Tecnología, Barrio Sarriena s/n 48940 Leioa
Para más información y registrarse en la jornada la siguiente web:
http://www.bsc.es/marenostrum-support-services/hpc-events-trainings/res-users-trainings/supercomputacion-euskadi-2013
 Mare Nostrum supercomputer
Introduction
The debuging of a program allow us to find the errors written in the source code. The tool that we are going to illustrate is the GNU gdb debuger.
Example
A user is trying to to Bader analysis of a Wavefunction with the aimpac tool extreme using a wavefunction obtained with Gaussian 09. When running the extreme program he obtains the following error:
extreme wave
forrtl: severe (64): input conversion error, unit 10, file
so extreme is not working. In order to figure out what is going on we will debug de conde. To do so we must compile it with the –g option, as follows:
gfortran -g EXT94b.f -o extreme
Then we start debuging.
gdb ./extreme
Once it is running, we have to pass the argument (the wavefunction stored in the wave file) to the program using:
set arg wave
and then run the programa:
run
Here is the whole sequence of the execution.
[cn0 7] ~ > gdb ./extreme
GNU gdb Fedora (6.8-27.el5)
Copyright (C) 2008 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type “show copying”
and “show warranty” for details.
This GDB was configured as “x86_64-redhat-linux-gnu”…
(no debugging symbols found
(gdb) set arg wave
(gdb) run
Starting program: /home/pobmelat/extreme wave
At line 3689 of file EXT94b.f
Fortran runtime error: Bad value during floating point read
Program exited with code 02.
(gdb)
In the 3689 line of the EXT94b.f I read
C READ IN
C
READ (IWFN,109) TOTE,GAMMA
The READ statement is using 109 format, which is defined in line 3703:
109 FORMAT(17X,F20.12,18X,F13.8)
And, the TOTAL SCF ENERGY AND -V/T is writen as follows in the gaussian 09 generated WFN:
” TOTAL ENERGY = -1263.592058754168 THE VIRIAL(-V/T)= 2.00956965"
The format of writing this line has changed in gaussian 09 to:
109 FORMAT(15X,F20.12,18X,F13.8)
I modified it, compiled it and extreme is working again.
Memoria 2011
El Servicio de Informática Aplicada a la Investigación (Cálculo Científico) IZO-SGI SGIKer ha publicado la memoria del 2011. Atención, no es la de 2012 sino la de 2011, sentimos el retraso. La memoria completa puede encontrarse en el siguiente enlace:
IZO-SGI year report (pdf)
El IZO-SGI de un vistazo
|
2009 |
2010 |
2011 |
| Cores de cálculo |
440 |
872 |
1.520 |
| Millones de horas de cálculo consumidas |
2,11 |
2,26 |
5,76 |
| Investigadores activos |
101 |
98 |
90 |
| Grupos activos |
53 |
40 |
42 |
| Cuentas nuevas |
49 |
33 |
33 |
| Satisfacción de los usuarios¹ |
8.9 |
8.8 |
8.8 |
| Artículos científicos² |
44 |
58 |
57 |
| Visitas web |
4.925 |
5.957 |
8.022 |
| Páginas vistas |
58.731 |
40.987 |
30.042 |
| Posts en el blog HPC |
– |
29 |
34 |
| Visitas del blog HPC |
– |
1.431 |
3.818 |
| Arina |
|
|
| Cores de cálculo |
320 |
752 |
1.360 |
| Millones de horas de cálculo consumidas |
2,07 |
2,11 |
5,20 |
| Promedio de ocupación |
75% |
47%³ |
74% |
| Trabajos enviados |
38.497 |
65.179 |
68.991 |
| Trabajos de más de 2 minutos⁴ |
28.377 |
50.624 |
51.735 |
| Tiempo promedio por trabajo⁵ |
76 horas |
44 horas |
101 horas |
| Tiempo medio de espera⁶ |
5,7 horas |
3,8 horas |
3,8 horas |
| Péndulo |
|
|
| Cores de cálculo |
120 |
120 |
120 |
| Millones de horas de cálculo consumidas |
0,02 |
0,15 |
0,09 |
| Ikerbasque |
|
|
| Cores de cálculo |
– |
– |
208 |
| Millones de horas de cálculo consumidas |
– |
– |
0,47 |
¹ Encuesta de satisfacción de los usuarios del Servicio realizada por SGIker.
² En los que se agradece al IZO-SGI.
³ El uso de 2010 es aparentemente bajo debido a que se instaló una ampliación de Arina que pasó de 300 cores a 752 y se hizo disponible a finales de Julio. Esto provocó que en Agosto y Septiembre Arina estuviese muy vacía y, debido a la magnitud de la ampliación, estos meses han tenido mucho peso en la media anual. En el mes de Noviembre ya se alcanzó un 76\% de ocupación.
⁴ Los trabajos de menos de 2 minutos se deben normalmente a trabajos fallidos que terminan inmediatamente en error. En cualquier caso, aun de no ser así, dada su corta duración no repercuten en el cluster.
⁵ No se han tenido en cuenta los trabajos de menos de dos minutos. Tal vez sea relevante tener en centa que con la ampliación se han adquirido procesadores más rápidos.
⁶ Los trabajos se ejecutan a través de un sistema de colas que asigna a cada trabajo los recursos que se le han solicitado y ordena su ejecución para optimizar el uso del cluster. El tiempo en cola es el tiempo que están esperando los trabajos hasta que se liberan los recursos que necesitan.
 Uso de Arina de Diciembre de 2010 a Noviembre de 2011.
La última lista (Noviembre de 2012) de los ordenadores más potenetes del mundo, top500.org, coronó a Titan como el supercomputador más potente. Al mismo tiempo la publicación de esta lista ha sido una de las más polémicas de los últimos tiempos dado que los responsables del superordenador Blue Waters, instalado por el National Center for Supercomputing Applications (NCSA) de la University of Illinois at Urbana-Champaign, decidieron no enviar los resultados de la potencia de Blue Waters para ser incluido en la lista.
 Modelo atómico elaborado en Blue Waters de la proteína CA ancontrada en cápsides del VIH. Blue Waters ha sido uno de los superordenadores más esperados por la comunidad de la supercomputación desde que se anunció su financiación por parte de la National Science Foundation (Agosto de 2007) y su posterior adjudicación para su construcción a Cray por 188 millones de dolares. A pesar de lo mareante de la cifra el costo de este tipo de ordenadores ronda este orden.
La polémica ha surgido, evidentemente, por que Blue Waters ha sido el primer superordenador en años que no envía los resultados del benchmark de potencia de cálculo a la lista top500.org, donde hubiese copado una de las primeras posiciones.
¿Porqué no enviaron los benchmarks?
La lista top500.org usa un único benchmark para medir la potencia de un ordenador: la ejecución del benchmark de linpack que resuelve un sistema denso de equaciones lineales. La característica más notable de este benchamark es que es muy intensivo desde el punto de vista de ejecución de operaciones en coma flotante, es decir, operaciones matemáticas con número reales. En este sentido se obtienen mejores resultados cuantos más cores de cálculo existan. Que estén bien comunicados también es necesario, pero otro tipo de requerimientos técnicos como sistemas de archivos y memoria RAM o más intangibles com usabilidad son secundarios.
La lista Top500 fue creada en 1993 con este benchmark y se considera por la comunidad como muy simplista, ya no es significativo de todas o una mayoría de las aplicaciones reales que hoy en día se ejecutan. No obstante, parece necesario enviar el resultado del benchmark a la lista “por que todos lo hacen”. Es más, parece que en muchas ocasiones la presión de logar un buen posicionamiento en la lista induce a que se configuren los sistemas para obtener el mejor rendimiento posible en el Linpack en decrimento de otras características, lo que podría penalizar las aplicaciones de la ciencia real que posteriormente se van a ejecutar en el superordenador.
Desde el NCSA hacen las siguientes objeciones al benchmark Linpack:
- El benchmark Linpack sólo mide sistemas de ecuaciones lineales densas.
Esto deja de lado muchos métodos y algoritmos usados hoy en día y sus necesidades computacionales. La ausencia de significado de este benchmark en ancho de banda a memoria, disco o interconexión se agravará en la evolución hacia la computación a exaescala. Se propone el uso de otros benchmark más realistas como NERSC SSP, DOD o el test NSF-Blue Waters SPP que ellos mismos desarrollan con 15 aplicaciones que van a correr en Blue Waters.
- No hay relación entre el posicionamiento en el top500 y la usabilidad del sistema
Muchos sistemas son incluidos en la lista sin estar todavía en producción incluso en fase de montaje. Esto produce hasta meses de diferencia entre la medida y cuando está realmente en uso por investigadores. Esto perturba el valor historico de la lista. Se propone la inclusión de sólo superordenadores y resultados de sistemas en producción.
- El Top500 fuerza a las instituciones a pobres configuraciones
La presión por conseguir un buen posicionamiento en la lista fuerza a las instituciones a sacrificar ancho de banda, memoria y almacenamiento en aras de incrementar los procesadores desequilibrando el supercomputador y reduciendo su eficiencia. Realizando estos sacrificios Blue Waters podría haber sido 3 o 4 veces más “potente”, pero habría limitado las aplicaciones que se podrían usar y dificultaría su programación haciéndolo menos usable. Se propone recoger más datos técnicos de los sistemas relacionados con anchos de banda, IO, etc para favorecer la configuración de sistemas equilibrados.
- El Top500 no reconoce el valor de un sistema.
Uno de los factores que afectan el posicionamiento en la lista, tanto como por ejemplo el diseño, las habilidades en programación o incluso la propia evolución de la tecnología, es el costo del superordenador. El top500 en cierto sentido releja la capacidad de financiación y enmascara otros valores añadidos como los mencionados (diseño, software, etc) inhibiendo posibles comparaciones entre sistemas. Se propone que se incluya el costo como dato, bien por que se proporciona directamente al ser un dato público o calculado por fuentes independientes. Esto permitirá comparaciones más perspicaces.
Aplicar estas nuevas correciones y otras nos ayudarán a tener nuevas métricas y listas mejor relacionadas con el rendimiento real de las aplicaciones. En el sentido en que evolucionamos a sistemas más complejos y exóticos, tener métricas adecuadas nos ayudará a tomar decisiones en la dirección correcta.
Referencias
Blue Waters Project Newsletter, diciembre de 2012.
The Computing Service of the UPV/EHU has opened Facebook and Twitter profiles to post there information about new posts in this blog, public announcements about the Service, etc. You can find our profiles in the following links
Facebook
Twitter
|
|
Comentarios