|
|
Las redirecciónes nos permiten en Linux redirigir la entrada o salida estándar desde o hacia un fichero, respectivamente. La tubería nos permite usar la salida de un comando como entrada para otro, permitiendo concatenar comandos.
Redirecciones
Primero señalar que en cuando hablamos de la entrada estándar se hace referencia, normalmente, a lo escrito a través del teclado y como salida estándar a lo envíado a la pantalla, aunque pueden ser otros los dispositivos definidos como estándar en algún caso especial. Las redirecciones se realizan con los símbolos > y < usando su similitud con unas flechas. Así con el símbolo > podemos redirigir la salida estándar desde un comando hacia un fichero. La redirección es muy útil cuando la salida es muy larga y no nos cabe en pantalla, cuando necesitamos o nos es conveniente guardarla en un fichero, etc. Veamos un ejemplo.
$ echo "Hola mundo"
Hola mundo
$ echo "Hola mundo" > saludo
$ cat saludo
Hola mundo
Como vemos en el ejemplo con el comando echo mandamos a pantalla un mensaje, pero si usamos la redirección > mandamos el mensaje al fichero saludo. Luego con el comando cat hemos mostrado el contenido del fichero que hemos creado. Para añadir información a un fichero existente, sin sobreescribirlo se usa >>. Veamos otro ejemplo:
$ echo "Hola mundo"
Hola mundo
$ echo "Hola mundo" > saludo
$ cat saludo
Hola mundo
$ echo "Ahora he sobreescrito el fichero saludo" > saludo
$ cat saludo
Ahora he sobreescrito el fichero saludo
$ echo "Pero ahora le he añadido otra línea" > saludo
$ cat saludo
Ahora he sobreescrito el fichero saludo
Pero ahora le he añadido otra línea
Como vemos en este ejemplo > destruye el contenido del fichero si existe pero >> añade la información al final.
El símbolo < permite enviar el contenido de un fichero como entrada estándar. Esto es útil, por ejemplo, en programas o comandos en los que introducimos o podemos introducir los argumentos por el teclado, de tal manera que podemos sustituirlos por un fichero. Un ejemplo tirivial con cat es:
$ echo "Hola mundo" > saludo
$ cat < saludo
Hola mundo
Tuberías
Las tubería es una redirección especial que nos permite enviar la salida de un comando como entrada de otro, para ellos se usa el símbolo |. Su gran útilidad es que nos permite concatenar comandos enriqueciendo mucho la programación. Veamos unos sencillos ejemplos con seq y head:
$ seq 1 5 |head -2
1
2
Redirecciones, avanzado
También exite la salida de error que va por otro ‘canal’ diferente. Así por ejemplo si el fichero file1 existe y el file2 no tenemos el siguiente comportamiento
$ ls file1 file2
ls: no se puede acceder a file2: No existe el archivo o el directorio
file1
$ ls file1 file2 > salida
ls: no se puede acceder a file2: No existe el archivo o el directorio
$ cat salida
file1
Como vemos, cuando hemos redirigido la salida al fichero salida, el mensaje de error que nos informa que el fichero file2 no existe sigue saliendo por pantalla. Para poder redireccinar también la salida de error tenemos que usar &> que nos dice que redireccionemos ambas salidas, así:
$ ls file1 file2 &> salida
$ cat salida
ls: no se puede acceder a file2: No existe el archivo o el directorio
file1
De hecho la salida estándar suele ir identificada con 1 (o &1 si va despues de > para diferenciarla de un fichero con nombre 1), y la salida de error con 2 (o &2) para poder hacer redirecciones individuales. Así, es equivalente a redirigir la sólo salida el siguiente comando:
$ ls file1 file2 1> salida
ls: no se puede acceder a file2: No existe el archivo o el directorio
$ cat salida
file1
Para redirigir la salida de error a un fichero
$ ls file1 file2 2> salida
file1
$ cat salida
ls: no se puede acceder a file2: No existe el archivo o el directorio
2>&1 o 1>&2 sirven para redirigir la salida de error a la estandar o viceversa para luego, por ejemplo, enviarla con una tubería a otro comando.
$ ls file1 file2 2>&1 salida |wc -l
2
De acuerdo a la lista top500.org de los ordenadores más potentes del mundo, a día de hoy Julio de 2013, el ordenador más potente del mundo es Tianhe-2 (Vía Láctea-2). Este superordenador está instalado en la National University of Defense Technology (NUDT) de China y es el sucesor tecnológico de Tianhe-1A, instalado en el National Supercomputer Center en Tianjin que ya fué número 1 del top500 en la lista de Noviembre de 2010.
(Nota: Ya existe un nuevo ordenador más potente, puedes leer sobre Tianhe-2 en este enlace)
 Tianhe-2 Supercomputer Tianhe-2 está formado por 16.000 nodos cada uno de los cuales tiene 2 procesadores Intel Xeon Ivy Bridge y 3 coprocesadores para acelerar los cálculos Xeon Phi. Esto hace un total de 3.120.000 cores de cálculo, 384.000 Xeon y 2.736.000 cores en los coprocesadores Phi. Es una novedad que tenga 3 coprocesadores por nodo pues lo habitual son uno o dos. Estos cores le dotan de un rendimiento teórico ejecutando operaciones matemáticas de 54,9 PFLOPS (Peta=10^15 FLoating-point Operation Per Second, 1.000.000.000.000.000 operaciones matemáticas por segundo) y en el benchmark LINPACK alcanza un rendimiento real de 33,9 PFLOPS, lo cual es casi el doble que el anterior número 1 Titan.
La red de interconexión entre los nodos es un diseño propio, TH Express-2, y trata de evitar que las comunicaciones sean un cuello de botella gracias al ancho de banda bidireccional de 16 GB/s, baja latencia y topología fat tree. Tianhe-2 usa el sistema operativo Kylin, basado en Linux, y también desarrollado por la NUDT y optimizado para HPC. El hecho de estar basado en un estándar como Linux le da mucha flexibilidad a la hora de ejecutar muchos códigos sin necesidad de reprogramarlos específicamente.
Tianhe consume 17.8 MW, que equivale aproximadamente al consumo de 27.000 familias, a pesar de lo cual es también en un supercomputador muy eficiente dado el alto número de FLOPS por watio que realiza, aunque cuando se anuncie la lista green500.org de los computadores energéticamente más eficientes del mundo probablemente ocupará entorno al puesto 40.
De acuerdo a la NUDT Tianhe-2 estará dedidado a aplicaciones de simulación, análisis y seguridad nacional.
Datos más relevantes
| Marca y modelo |
Diseño propio |
| Nº de cores |
3.120.000: 384.000 cores xeon y 2.736.000 cores Phi |
| Procesador |
Intel Xeon E-2692 de 12 cores a 2.2 GHz |
| Coprocesador |
Intel Phi 31S1P de 57 cores a 1,1 GHz |
| Interconexión |
TH Express-2 |
| Sistema Operativo |
Kylin |
| FLOPS teóricos |
54,9 PetaFLOPS |
| FLOPS Linpack |
33.9 PetaFLOPS |
| Potencia eléctrica |
17.8 MW |
| FLOPS/W |
1.9 GigaFLOPS |
Un script en linux es un programa escrito en el lenguaje de Linux, es decir, una concatenación de comandos. Los scripts son muy útiles para realizar acciones que repetimos habitualmente y que suponen la ejecución de varios comandos o para ejecutar una concatenación compleja de acciones, que es más fácil de ir escribiendo y corriguiendo si lo hacemos como si se tratase de un programa. De este modo escribimos todos los comandos que queremos ejecutar en un fichero de texto con un comando por línea. Así ya hemos creado un script que cuando lo ejecutemos será equivalente a ejecutar todos los comandos que tenemos en el script.
 Tux La potencia de los scripts en Linux tal vez no se aprecie con el programa que ponemos como ejemplo, pero conforme vaya aumentando nuestro conocimiento de Linux, con más comandos y más complejos podremos automatizar tareas muy complejas. Con este post, de hecho creamos, la sección de “comandos avanzados”, donde describiremos comandos de interés para la programación de tareas complejas.
Veamos un ejemplo sencillo. Escribiremos un fichero de texto plano (no un .odt, .xdoc o similar que aparte del texto visible contiene mucha información “oculta” para darle el formato) que contenga las siguientes líneas y que llamaremos hola.sh:
#!/bin/bash
mkdir TMP
cd TMP
touch newfile.txt
echo "Hola mundo, el fichero ha sido creado"
ls
En este simple script hemos creado el directorio TMP con mkdir, nos hemos metido dentro de este directorio con cd, hemos creado un fichero vacío llamado newfile.txt con el comando touch, mostramos en pantalla un mensaje empleando el comando echo y listamos los ficheros que existen en el directorio con el comando ls. La primera línea es un poco especial e indica que “lenguaje queremos utilizar” (que shell). En este caso usamos bash que es el más común.
No obstante, no vamos a poder ejecutar el fichero hola.sh pues es un fichero de texto sin permiso de ejecución. Para darle permiso de ejecución usamos el comando chmod.
Tras darle permiso para ejecutarse a nuestro script hola.sh, dependiendo de la configuración de nuestro Linux, para ejecutar nuestros scripts debemos indicarle el donde está, en este caso si está en nuestra carpeta se indica explícitamente precediendo el nombre con “./". Si lo ejecutamos obtenemos:
$ chmod u+x hola.sh
$ ./hola.sh
Hola mundo, el fichero ha sido creado
hola.sh newfile.txt
Donde nos muestra en una línea el mensaje del que hemos enviado a pantalla con echo y en la siguiente el resultado del comando ls.
La potencia de los scripts en Linux tal vez no se aprecie con un programa tan sencillo, pero conforme vaya aumentando nuestro conocimiento de Linux, con más comandos y más complejos podremos automatizar tareas muy complejas.
Linux es un sistema operativo multiusuario y permite varios usuarios en un mismo ordenador, además estos usuarios pueden estar organizados en grupos. Por ello existen 3 roles diferentes: el usuario que es uno mismo, el grupo al que pertenece el usuario y que puede tener más miembros y todo el mundo. Además, para asegurar la privacidad en linux todos los ficheros tienen 3 tipos de permisos, de lectura “r” (read), de escritura “w” (write) y de ejecucion “x” (eXecution), que según estén activados o no nos permiten leer, escribir o ejecutar un fichero, respectivamente. Asó pues con 3 roles y 3 permisos por rol tenemos 9 permisos que podemos gestionar. Para ver los permisos podemos listar los ficheros (ls) indicándole que nos dé más información el formato largo (-l). Por ejemplo:
$ ls -l hola.sh
-rw-rw-r-- 1 jose departamento 0 abr 24 10:24 hola.sh
El primer carácter si es “-” nos indica que es un fichero, en caso de directorios aparece “d“. Los 3 siguientes caracteres son los permisos del usuario. Como vemos tiene permisos de lectura y escritura (rw). El de ejecución no está activado y aparece “-“. Los 3 siguientes son para el grupo y tiene los mismos permisos, lectura y escritura (rw). El resto de usuarios en el ordenador solo tienen permisos de lectura (r).
Para cambiar los permisos de nuestros ficheros se usa el comando chmod. La manera más intuitiva es indicar a quien – u, g,o o a para indicar usuario, grupo, otros o a todos (all) respectivamente – le queremos dar (+) o quitar (-) permiso de lectura, escritura o ejecución (r, w o x respectivamente). Veamos un ejemplo donde primero añadimos al usuario permiso de ejecución del fichero hola.sh y luego eliminamos permiso de lectura al todo el mundo y finalmente le volveremos a dar permiso de lectura al usuario.
$ ls -l hola.sh
-rw-rw-r-- 1 jose departamento 0 abr 24 10:24 hola.sh
$ chmod u+x hola.sh
$ ls -l hola.sh
-rwxrw-r-- 1 jose departamento 0 abr 24 10:24 hola.sh
$ chmod a-r hola.sh
$ ls -l hola.sh
--wx-w---- 1 jose departamento 0 abr 24 10:24 hola.sh
$ chmod u+r hola.sh
$ ls -l hola.sh
-rwx-w---- 1 jose departamento 0 abr 24 10:24 hola.sh
Como vemos al usuario le ha aparecido el permiso de ejecución x, también tiene de lectura y escritura y el grupo tiene de escritura
Superkonputazioaren munduan, top500 delako zerrenda erreferente bat da (http://www.top500.org), bertan, munduko potentziarik handieneko 500 ordenagailuak ageri baitira. Zerrenda hau urtean bi aldiz eguneratzen da, ekaina eta azaroan antolatzen diren ISC (International Supercomputing Conference) bileretan.
1993. urtean sortu zen, superkonputazio munduaren joerak aztertzeko eta superkonputagailuen arteko aladaraketa konparagarriak egin ahal izateko. Oinarri beazala, LINPACK liburutegietan (algebra linearreko liburutegi bat) ageri den LINPACK testa aukeratu zen, beraz, top500 zerrenda test hau azkarren exekutatzen duten ordenagailuen zerrenda da. Orokorrean, zerrenda honetako ordenagailuek test hauek optimizatzen dituzte, emaitzak onak izan eta zerrendan sartu ahal izateko, honek dakarren ospeagatik.
Zerrenda sortu zenetik, bertako sistemen potentzia 14 hilabetero (gutxi gora bera) bikoiztu dela ikusten da azpiko irudian. Moore-en legearekiko hobekuntza nabarmena da. (Moore-en legea: zirkuitu integratuen transistore kopurua bi urtero bikoizten da). Moore-en eratorria den bigarren lega bat ere nabarmen hobetzen du (honek prozesgailuaren eraginkortasunaren hobekuntza kontutan hartzen eta potentzia 18 hilabetero hobetzen dela dio). Eraginkortasun hobekuntza honek agerian uzten du arlo honek duen garrantzia. Eragingortasun hau lortzeko, hainbat eragileek, instituzioeek zein makina fabrikatzaileek, egindako esfortzua nabarmena da, kalkulu zientifikoak gaur-egun duen garrantzia erakusten digularik
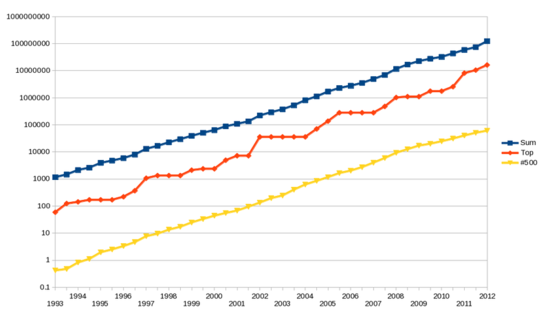 Top500-eko superkonputagailuen eraginkortasunaren garapen exponentziala GFLOP-etan. Lerro gorria superkonputagailu azkarrenari dagokio, horia 500.-ari eta urdina lista guziko ordenagailuen eraginkortasunaren baturari (Wiki Commons). Superkonputagailuek 1993. urtea ezkero jasandako garapena modu sinple eta argian ikusi daiteke top500 zerrendan. Bertan, prozesagailu kopuruak, prozesagailu motak, fabrikatzaileak, sistema eragileak, kokapen geografikoen aldaketak etb. erraz aztertu daitezke. Kalkulu zientifikoaren gida bat bezala erabili daiteke superkonputazioaren joerak (prozesadore motak, sare motak …) ikusteko edo etorkizunean estandarizatu daitezkeen teknologia berrien froga eremu bat bezala ere ikus daiteke.
Informatikaren islada orokor bat ere eman diezaguke, edo zergaitik, gizartearen zientzia eta teknologiarena garapenarena, batez ere ordenagailu hauek zeinek eraiki eta non kokatuta dauden begiratzen badugu. Adibidez, azaroko 2012 zerrenda aztertuz ikus dezakegu:
- Prozesagailuen %99.4-a enpresa amerikarrak egindakoak direla (IBM, Intel eta AMD). %0.6-a Fujitsu Japoniarrenak.
- Ordenagailu hauek egiten dituzten enpresak begiratuz ere %90 inguru EEBB-ak direla.
- Sareari dagokionez, %45-ak infiniband sare mota dutela eta %37-ak Gigabit ethernet.
- Sistema eragileak aztertuz, %94-ak Linux erabiltzen dutela, %0.6-ak windows.
- Kokapenaren aldetik, %50 EEBB, %21 Europan, %14.4 Chinan eta %6-a Japonen daudela. Hego hemisferioan 9 besterik ez 7 Autralian eta 2 Brasilen.
Datu hauek sakon aztertu beharrik gabe, hainbat ondorio nabarmen erraz atera daitezke.
2006. urtean green500 lista sortu zen. Bertan, top500-eko ordenagilu berak ageri dira berriz, baina erabilitako Watt bakoitzeko ordenatuta, hau da FLOPS/W erlazioa begiratuz, non FLOPS (FLoating-point Operations per Second) den, eta W Watt potentzia unitatea. Superkonputagailuen energi behar izugarria dela eta, energiaren aldetik eraginkorrenak nabarmentzeko sortu zen zerrenda hau. Titan, 2012. Azaroko top500 zerrendako lehenengoa da. Bere kontsumoa 9.000 etxebizitzen adinakoa da, hala ere, konputagailu hau oso eraginkorra da green500 listako 3. delarik.
Goian esan den bezala, badaude munduan hainbat superkonputagailu zerrendako lehenegoak bezain potenteak direnak eta arrazoi desberdinengaik ageri ez direnak, Blue Waters da horietako bat (ikus Blue Waters el superordenador rebelde eta Titan vs. Blue Waters bien top500 lehena eta Blue Waters-en arteko desberdintasunak ikusteko eta Titan, 2012. Azaroko top500 zerrendako lehenengoa ).
OHARRA: Posta hau leheango erdaraz idatzi genuen El Top de los ordenadores más potentes del mundo postaren itzulpen osatu bat da.
En este post comparamos Titan, el superordenador más potente del mundo, y Blue Waters, el controvertido supercomputador al no enviar resultados para entrar en la lista donde debería de ocupar uno de los primeros puestos.
 Titan supercomputer A día de hoy Titan es el superordenador más potente del mundo según la lista del top500.org (se actualiza cada 6 meses, ¿Qué es el top500?). No obstante, como ya comentamos en este post anterior el ordenador Blue Waters decidió no enviar el resultado de su benchmark Linpack al top500.org para ser incluido en la lista. El motivo es que consideran el benchmark Linpack muy simple, que no mide más que ciertas características muy concretas de un supercomputador y que el orientar el diseño y los esfuerzos a conseguir un buen Linpack, y por tanto un buen posicionamiento en el top500.org, puede perjudicar el rendimiento general de la máquina en aplicaciones reales.
En la siguiente tabla comparamos las características de ambos supercomputadores. Mencionar que para construir Titán se desmantelaron los nodos de su predecesor Jaguar y se instalaron en la misma infraestructura los nuevos nodos y redes de Titan, lo cual habrá influenciado en un menor costo. Recientemente el Lawrence Livermore National Laboratory, que alberga a Titan, ha llegado a un acuerdo con DataDirect para instalar en Titan un potente sistema de ficheros paralelo basado en Lustre con un ancho de banda de más de 1 TB/s y 40 PB de capacidad, que no se incluyen en la tabla.
Característica
|
Titan
|
Blue Waters
|
| Vendedores |
Cray/AMD/NVIDIA |
Cray/AMD/NVIDIA |
| Procesadores |
Interlagos/Kepler |
Interlagos/Kepler |
| Rendimiento medido |
17.6 |
— |
| Rendimiento pico teórico |
27 |
11.6 |
| Rendimiento pico teórico CPUs |
3 PFLOPS |
7.1 PFLOPS |
| Rendimiento pico teórico GPUs |
24 PFLOPS |
4.5 PFLOPS |
| Nodos totales |
18688 |
25712 |
| Nodos con GPUs |
18688 |
3072 |
| Memoria RAM total |
688 (TB) |
1510 (TB) |
| Interconexión |
Gemini, 3D Torus |
Gemini, 3D Torus |
| Almacenamiento de disco on-line |
20 (?) PB |
26 PB |
| Ancho de banda a disco |
0.4-0.7 TB/s |
<1 TB/s |
| Almacenamiento en cinta |
15-30 PB |
300 PB |
| Ancho de banda a cinta |
7 GB/s |
<100 GB/s |
| Almacenamiento de disco on-line |
20 (?) PB |
26 PB |
| Costo |
~97 millones de $ |
188 millones de $ |
La máquina virutal java (JVM) es un programa que ejecuta programas realizados en el lenguaje de proposito general Java. Una de las grandes ventajas de Java es que sus programas pueden correr en cualquier sistema operativo – Linux, Solaris, Windows, etc – una vez se haya instalado la máquina virtual java en el ordenador. Es decir, no es necesario ni compilarlo, ni modificarlo para adaptarlo al sistemas operativo nativo del ordenador.
En la supercomputación o HPC (High Performance Computing) se mantiene a día de hoy la percepción de que Java es un lenguaje que ofrece menos rendimiento que los comúnmente utilizados C, C++ o Fortran. Esta creencia tan fuertemente arraigada tiene su origen en las primeras versiones de la JVM. En 1995 cuando apareció la primera versión de Java su rendimiento si era menor al de C++, sin embargo, la JVM ha sufrido notables mejoras de funcionalidad desde su primera versión. Si además tenemos en cuenta las ventajas inherentes que nos ofrece Java no resulta complicado comprender que su uso en HPC se vea incrementado día a día. Se pueden destacar dos capacidades principales que hacen de Java un lenguaje con el potencial necesario para su uso en HPC: “el recolector de basura” y “el compilador Just-In-Time”.
El recolector de basura (Garbage Collector) se encarga de liberar la memoria no usada, lo cual facilita el trabajo de los programadores, deshaciéndose de la necesidad de liberar la memoria explícitamente en las aplicaciones permitiendo un código más limpio, más seguro y unas aplicaciones más robustas. Aunque esta ventaja también implica un gasto mayor de memoria del que otros lenguajes requieren. El compilador Just-In-Time (JIT), que ofrece la posibilidad de la creación y compilación de nuevas funciones mientras la aplicación se esta ejecutando, permite mejorar el rendimiento.
Cálculo numérico con Java
En lo concerniente a las operaciones de cálculo, Java es incapaz de seguir a otros lenguajes como C, tardando tres o incluso cuatro veces más en completar dichas tareas. Esto se debe a que Java no dispone de soporte nativo para números complejos, arrays multidimensionales y que las funciones trigonométricas no se encuentran optimizadas.
Proyectos de supercomputación en Java para el procesamiento de datos
En los últimos dos años se ha avanzado mucho en lo que a supercomputación con Java se refiere, han surgido grandes proyectos destinados tanto al cálculo científico, como al intercambio de grandes cantidades de información en los sectores financieros. Incluso en la Organización Europea para la Investigación Nuclear (CERN) se han llevado a cabo grandes proyectos con Java.
 The data collected by the Gaia satellite will be analized using Java. Dentro del ámbito del tratamiento de datos científicos en HPC mediante el uso de Java podemos encontrar la misión astrométrica espacial Gaia. El objetivo de esta misión es enviar una sonda que orbitará alrededor del Sol a una distancia de 1,5 millones de kilómetros de la Tierra durante los próximos 5 años para crear un mapa tridimensional de nuestra galaxia. Se estima que a lo largo de los cinco años que durará la misión la sonda observará miles de millones de estrellas más de 70 veces para obtener datos como: luminosidad, temperatura, gravitación, la composición en elementos químicos… Esta ingente cantidad de datos se analizarán con Java.
Un supercomputador esta formado por diversos nodos de cálculo interconectados entre sí que trabajan conjuntamente. Para esta colaboración es necesaria que los nodos se intercambien información. El modelo más utilizado para lograrlo es el paso de mensajes (Message Passing Interface, MPI), y su equivalente en Java es Message Passing in Java (MPJ). En este proyecto habría que destacar la creación de una aplicación Java llamada “MPJ-Cache”. Este middleware mediante el uso de MPJ ofrece una interfaz de programación (API) de alto nivel que ofrece al programador funcionalidades como: almacenamiento temporal en cache, precarga de datos, división y recombinación de archivos grandes, precarga de datos… de forma distribuida en los nodos. El uso de la misma registró un rendimiento total de hasta 100 Gbps.
En cuanto al procesamiento de grandes cantidades de datos en Java orientados a la supercomputación nos encontramos con la herramienta “LMAX Disruptor”. Fue creada inicialmente para manejar el procesamiento de datos en un entorno financiero, sin embargo, debido al gran avance que ha supuesto aspira a llegar más allá. El problema inicial es que que los bloqueos en las colas que requieran la mediación del Sistema Operativo resultan muy costosos, por ello decidieron crear este framework libre de bloqueos. Para lograrlo hace uso del “magic ring buffer” que, como indica su propio nombre, es un anillo el cual se usa de buffer para pasar de un proceso a otro. Cada registro del buffer guarda un puntero al siguiente proceso. Este sistema sustituye el uso de las colas lo cual ofrece un mayor rendimiento al evitar los bloqueos, sin embargo, incrementa la complejidad del propio código.
Conclusión
Es posible que Java aun tarde años en acabar por alcanzar a C++ y Fortran en su uso, sin embargo la portabilidad que nos ofrece el propio Java es un gran punto a su favor. Esto unido a las diversas librerías y herramientas dota a Java con las funcionalidades necesarias para suplir con creces las necesidades de proyectos de supercomputación. A pesar de ello, tiene carencias difíciles de ser pasadas por alto, como las dificultades mencionadas para los cálculos. Otra desventaja añadida al uso de Java en comparación con otros lenguajes es la memoria, Java requiere más de la que C++ utiliza. De modo que, si bien Java dispone de las capacidades necesarias para el HPC, no siempre resulta ser eficiente en todos los aspectos necesarios, lo cual le augura un futuro incierto como entorno de desarrollo general en HPC, aunque si es viable en ciertos campos.
Gorka Frade Camino,
Alumno en prácticas del centro IEFPS Elorrieta-Erreka Mari en prácticas en el IZO-SGI.
Referecias
Tesis de Aidan Fries. The use of Java in large scientific applications in HPC environments.
Java vs C++ performace.
Wikipedia. High performance computing.
Wikipedia. Compilación en tiempo de ejecución.
Wikipedia. Java.
Wikipedia. Java performance.
Análisis del rendimiento de Java.
LMAX Disruptor.
Regla mnemotécnica
seq: Sequence
El comando seq escribe la secuencia de números enteros indicada entre un inicio y un final:
seq Inicio Final
o especificando el incremento
seq Inicio Incremento Final
Ejemplo1. Imprimir los números del 1 al 5:
$ seq 1 5
1
2
3
4
5
Ejemplo 2. Imprimir la tabla del 8:
$ seq 0 8 80
0
8
16
24
...
Ejemplo 3. Imprimir una secuencia hacia atrás.
$ seq 3 -1 -2
3
2
1
0
-1
-1
Ferran Hurtado se centrará en la geometría computacional, una de las disciplinas que han surgido recientemente y en sus aplicaciones a la robótica, la medicina, la geografía, la informática gráfica, el diseño, el fútbol, el reconocimiento de formas, etc. Además, contenedrá algunos apuntes básicos sobre la naturaleza de las matemáticas y su papel en la tecnología
La exposición será de carácter divulgativo, requiriendo tan solo conocimientos de matemáticas propios de la enseñanza primaria, y tiene como objetivo hacer conscientes a los asistentes de que hay matemáticas detrás de cada tecnología, y de que si ésta es nueva, buena parte de las matemáticas que la subyacen también lo han de ser. De este modo, el incesante desarrollo de las matemáticas, y entre ellas el de la geometría computacional, contribuye a mejorar constantemente nuestra vida cotidiana
2 de Mayo de 2013 a las 19:30 en la biblioteca de Bidebarrieta de Bilbao.
Conferenciante
Ferran Hurtado es Catedrático de Matemática Aplicada en Barcelona, en la Universidad Politécnica de Cataluña, donde dirige un reconocido grupo de investigación en geometría discreta y computacional. Ha escrito varios libros y capítulos de libro, que van desde textos de bachillerato hasta temas propios de su especialidad, ha publicado más de un centenar de artículos en revistas arbitradas, ha dirigido quince tesis doctorales y ha liderado numerosos proyectos de investigación, tanto nacionales como internacionales.
 Collision of convex shapes
El pasado 18 de Abril terminó en Arina, el clúster del Servicio de Informática Aplicada a la Investigación (Cálculo Científico) de la UPV/EHU, el cálculo más largo realizado hasta ahora en el Servicio. Este cálculo fue lanzado el 1 de Enero de 2012 por lo que ha estado ejecutándose ininterrumpidamente 1 año, 4 meses, 16 días y 8 horas, 11335 horas en total. Este cálculo ha supuesto un récord en el Servicio de Cálculo se ejecutan trabajos que duran desde unos pocos minutos hasta algunos meses, aunque no son normales cálculos tan largos como éste.
El cálculo se ha ejecutado empleando 12 cores simultáneamente en paralelo, por lo que el tiempo de cálculo equivale a usar un core durante 15.5 años lo que también ha supuesto un hito. En este sentido existen cálculos que usan muchos más cores en forma paralela (64, 128, etc) y que en menos tiempo real acumulan mucho tiempo de cálculo, aunque ninguno ha llegado a los 15.5 años logrados esta semana. Por supuesto, en clústers más grandes donde se pueden ejecutar fácilmente cálculos en miles de procesadores estos números se quedan ridículos. Por como está programado el código empleado, éste no puede ejecutarse en varios nodos, es decir en mucho cores, en paralelo por lo que está limitado a usar un único nodo, en este caso con 12 cores.
A pesar del modesto tamaño de Arina lo que este cálculo ha demostrado es la gran estabilidad y fiabilidad del clúster que gracias a la flexibilidad del servicio, calidad del mismo, y a los servicios y CPD (sala de máquinas) proporcionados por las TIC de la UPV/EHU permiten una operación ininterrumpida tan larga.
 Artistic representation of a Coulomb explosion of clusters El profesor Ikerbasque Andreas Heidenreich trabaja en el estudio teórico de explosiones de Coulomb. Estas explosiones se producen cuando se ionizan de forma extrema y ultrarápida clústers de átomos quedando estos fuertemente ionizados con carga positiva lo que provoca una fuerte repulsión entre los núcleos que salen despedidos a velocidades altísimas. Estas explosiones de Coulomb pueden tener aplicaciones futuras en fusión fría, creación de neutrones o estudios de síntesis en las estrellas. La producción experimental de estas explosiones se realiza en laboratorios singulares y son tremendamente caras, por eso su comprensión teórica es tan importante y económicamente mucho más asequible.
Más información sobre explosiones de Coulomb
Grupo de Química Teórica de la UPV/EHU. Coulomb Eztandak: Fusio hotzarako bidea?
|
|


Comentarios