|
|
Regla mnemotécnica
date: Fecha en ingles.
El comando date nos permite imprimir la fecha de hoy en muchísimos formatos. También nos permite extraer solo el día, mes, día de la semana, etc. Es útil en la ejecución de scripts pues nos permite saber cuando se ha ejecutado, por ejemplo si estos se ejecutan de forma automática en ciertas cirscustancias. Si lo ejecutamos sin argumentos nos imprime la fecha de hoy en formato largo.
$ date
mié sep 25 12:31:17 CEST 2013
Si queremos controlar el formato tenemos que usar una sintaxis tipo
$ date +formato
donde en formato tenemos muchas posibilidades. Algunas de ellas las indicamos en la siguiente tabla. No obstante, lo mejor para conocer todos los posibles formatos es usar el comando de ayuda man con man date que nos mostrará el manual de date.
| %a |
Día de la semana abreviado (lun, mar, etc) |
| %A |
Día de la semana (lunes, martes, etc) |
| %b |
Més abreviado (ene, feb, mar, abr, etc |
| %e |
Día del mes (1,2,..,31) |
| %D |
Fecha en formato dd/mm/aa |
| %H |
Hora en formato 00,..,23 |
| %M |
Minutos en formato 00,..,59 |
| %T |
Hora completa en formato hh:mm:ss (24 horas) |
| %W |
Semana del año, el lunes el primer día (00,..,53) |
Así por ejemplo:
#Manual de date
$ man date
#Diferentes comandos de date
$ date +%a
lun
$ date +%T
22:15:35
$ date +%H%M
2215
También se puede intercalar texto como en los siguientes ejemplos:
#Sin texto
$ date +%H%M
2215
#Con texto, no podemos incluir espacios en blanco
$ date +hora%Hdia%M
hora22dia15
#Pero podemos formatearlo mejor entrecomillando el texto
$date +"hora: "%H" - dia: "%M
hora: 22 - dia: 15
Se puede usar el comando date para indicarle una fecha específica con la opción -d como en los ejemplos:
#La fecha de ayer
$ date -d yesterday
mar sep 24 12:31:17 CEST 2013
#La fecha de mi cumpleaños
$ date -d 02/17/76
mar feb 17 00:00:00 CEST 1976
$ date -d 02/17/76 +"Nací un "%A
Nací un martes
¿Cómo serán los superordenadores dentro de 50 años?¿Para qué servirán? ¿Cómo funcionarán? En esta charla se explicará algunos de los avances obtenidos en los últimos años en Física Cuántica que nos permitirán responder todas estas preguntas
… y alguna más.
Lunes 30 de Septiembre a las 19:15 en el Teatro Victoria Eugenia de Donostia.
Enmarcado dentro del evento Passion for Knowledge – Quantum 13.
Todas las conferencias públicas son de acceso gratuito previa inscripción.
There will be English translation. La conferencia será retransmitida por la web.
Sobre el autor
Juan Ignacio Cirac (Manresa, 1965) se licenció en Física Teórica en la Universidad Complutense de Madrid en 1988 y obtuvo el doctorado en 1991. Miembro de la Sociedad Max Planck desde 2001, es desde ese mismo año director del Instituto Max Planck de Óptica Cuántica (Garching, Alemania).
Experto en computación cuántica y sus aplicaciones en el campo de la información, su línea de investigación se centra en la teoría cuántica de la información. Según sus teorías, el ordenador cuántico revolucionará el mundo de la información, ya que permitirá una comunicación más eficaz y una mayor seguridad en el tratamiento de datos y transferencias bancarias.
Es miembro correspondiente de las academias de Ciencias Española y Austriaca y de la Sociedad Americana de Física. Su trabajo ha sido objeto de numerosos galardones, entre los que destacan el Premio Felix Kuschenitz de la Academia Austriaca de Ciencias en 2001, el Quantum Electronics de la Fundación Europea de Ciencia en el 2005, el Premio Príncipe de Asturias a la Investigación Científica y Técnica en 2006, el Premio Fundación BBVA Fronteras del Conocimiento y la Cultura en Ciencias Básicas 2008, medalla Franklin en 2010, y más recientemente, el Premio de Física 2013 de la Wolf Foundation.
1.6 miloi definizio handiko filma streaming bidez emateko banda zabalera nahikoa duen konexioa lortu da. Lotura honek 8 terabit segunduko (Tbps), 8 miloi mega, banda zabalera du. Luzera handiko superkanal optiko hau Amsterdam (Herberherak) eta Hamburgoren (Alemania) artean egin da Infineraren Intelligent Transport Network erabiliz.
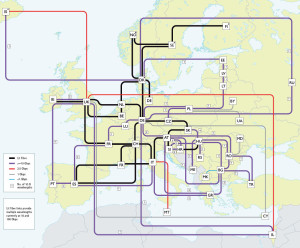 GÉANT enbor-sarearen topologia Lotura hau DANTE-k (Delivery of Advanced Network Technology to Europe) egin du. Europar erakunde honek, Europako ikerkuntza instituzioen arteko abiadura handiko konexioa eraikitzen eta kudeatzen du. Horrela, DANTEk unibertsitateak, ikerkuntza zentroak eta azpiegitura zientifikoak (CERN adibidez) lotzen ditu. Marka hau GÉANT sarea erabiliz egin da, sare hau, nazioarteko sare zientifiko eta hezkuntza sarea, lotzen dituen sare fisikoa da. GÉANT-ek 10.000 erakunde eta 50 miloi ikertzaile konektatzen ditu.
Orain dela gutxi DANTEk ere jakinaraiz du GÉANTeko enbor-sarea 2 Tbps-ra eguneratu duela baliabide konputazionalen arteko loturak hobetzeko. GÉANTeko IP enbor-saretik 1.000 terabyte (1 byte = 8 bit) transmititzen dira egunero. Datu zientifikoen sorrerak, azterketak eta horien elkarbanatzeak, eraginkortasuan handiko konputazioak eta grid-ak osatzen duten e-azpiegiturak estresatzen dituzte. CERNen etorkizuneko Square Kilometre Array teleskopioa (munduko handiena izango dena) edo bioinformatikako proiektuak sortzen dituzten datuen banaketa, azterketa, metaketa eta eskuragarritasuna eraginkor bermatu behar dira. GÉANT sareak izugarrizko garrantzia dauka Europa mailan zeregin honetan.
GÉANT sarea eguneratzeko proiektua epe luzeko inbertsioa izan da, enbor-sareko 50.000 Km berritu eta ekipamendu zaharra puntako teknologia duen transmisio gailuekin ordezkatuz. Teknologi berri hauek zerbitzu gehiago eta fidagarritasun handiagokoak bermatuko dituzte.
Oharra: Bidaliketa hau erderaz publikatutakoaren Record en ancho de banda por la red científica europea GÉANT-DANTE itzulpena da.
top500.org zerrendaren arabera munduko ordenagailu ahaltsuena gaur egun, 2013ko Iraila, Tianhe-2 (Esne-bidea-2) da. Superkonputagailu hau Txinako National University of Defense Technology (NUDT) unibertsitatean dago eta Tianhe-1A superkonputagailuaren ondorengo teknologikoa da, azken hau Tianjingo National Supercomputer Center-ean dago eta 2010ko Azaroko top500.org zerrendan lehengo postua lortu zuen jada. top500.org zerrenda urtean bi aldiz eguneratzen da.
(Nota: Badago superodenadore bat ahaltsuagoa, Tianhe-2-ri buruz irakurri dezakezu ezteka honetan)
 Tianhe-2 Supercomputer Tianhe-2 16.000 nodoz osatuta dago. Nodo bakoitzak 2 Intel Xeon Ivy Bridge prozesagailuz eta 3 Xeon Phi koprozesagailuz, kalkulu matematikoak azkartzeko, osatuta dago. Guztira 3.120.000 kalkulu kore ditu 384.000 Xeon koretan eta 2.736.000 Phi koretan banatuta. Hiru koprozesadore izatea berrikuntza bat da ohikoena 1 edo 2 izatea baitzen orain arte. Kore kopuru izugarri honek aplikazio matematikoak egikaritzeko 54,9 PFLOPS-etako (Peta=10^15 Floating-point Operation Per Second, 1.000.000.000.000.000 segundo bakoitzeko operazio kopurua) errendimendu teorikoa ematen dio eta LINPACK benchmarka egikaritzen 33,9 PFLOPS-etara iristen da, ia zerrendako aurreko lehenengo postua zuen Titan superordenagailuaren bikoitza.
Nodoen arteko komunikazio sarea beraiek diseinatutako elektronika darama, TH Express-2, eta komunikazioek errendimendua murriztu dezaten saihestu nahi du bere 16 GB/s-etako banda-zabalera bi-direkzionala, latentzia baxua eta fat tree topologiari esker. Tianhe-2 Linuxen oinarritutako eta HPCrako optimizatutako Kylin sistema eragilea darama, NUDT-n garatutakoa baita ere. Linux sistema eragilean oinarrituta egoteak erraztasun asko ematen ditu programak exekutatzeko berprogramazio beharrik ez dagoelako, Linux oso zabalduta baitago zientzia arloan.
Tianhe-2 superkonputagailuak 17.8 elektrizitate MW erabiltzen ditu, gutxi gorabehera 27.000 familiek behar duten elektrizitatea. Hala ere energetikoki oso ordenagailu eraginkorra da FLOPS asko egiten baititu watio bakoitzeko, 1,902 MFLOPS/W hain zuzen ere. Izan ere energetikoki munduko ordenagailu eraginkorren green500.org zerrendan 32. postuan dago.
NUDT-ren arabera Tianhe-2 superordenagailua simulazioentzako, analisientzako eta nazioaren segurtasunerako erabiliko da.
Datu adierazgarrienak
Marka eta modeloa
|
Diseinu propioa |
Kore kopurua
|
3.120.000: 384.000 xeon kore eta 2.736.000 Phi kore |
| Procesagailua |
Intel Xeon E-2692, 12 koretakoa 2.2 GHz-etara |
| Coprocesador |
Intel Phi 31S1P, 57 koretakoa a 1,1 GHz-etara |
| Interconexioa |
TH Express-2 |
| Sistema eragilea |
Kylin |
| FLOPS teorikoak |
54,9 PetaFLOPS |
| FLOPS Linpack |
33.9 PetaFLOPS |
| Potentzia elektrikoa |
17.8 MW |
| FLOPS/W |
1.9 GigaFLOPS |
Superkonputagailu terminoa 60. hamarkadan sortu zen Control Data Corporation (CDC) konpainiak eraikitako ordenagailuen ezaugarriak zirela eta. Ordenagailu hauek nagusiki Seymour Cray-k diseinatzen zituen. 1974. urtean, Seymour Cray-k CDC utzi eta Cray enpresa sortu zuen. Superkonputagailu hauek berrikuntza ugari zituzten bere garaikideekiko. Paralelismoa kontutan hartzen zuten, eraginkortasun piko oso altuak lortzen zituztelarik, memoria eta biltegiratze sistemak bereziak zituzten ere. Hasiera hartan, superkonputagailuak ordenagailu bakar bat ziren, prozesagailu bakarra eta memoria bakarrarekin. Ondoren, prozesagailu bektorial gutxi batzuk izatera pasa ziren. Prozesagailu hauek oso eraginkorrak ziren Kalkulu Zientifikoan, bektore zein matrize bateko osagai askorekin eragiketak egin baizitzaketen erloju ziklo bakar batean (gaur egun nagusitzen diren prozesagailu eskalarrak datu bakar batekin egiten dituzte eragiketak ). 90. hamarkadararte superkonputagailu hauek ziren ahaltsuenak, eta antzekoak eraikitzen zituzten hainbat konpainia sortu baziren ere, Cray izan zen nagusia. Ordenagailu hauek oso garestiak ziren, hainbat miloi dolaretako kostua zuten, eta oso instituzio gutxi ziren halako baliabideak izan zitzaketenak. Ordenagailu hauek, ordenagailu bakar bat izanik, tamainaz handiak izaten ziren (ikus 1.- Irudia).
 1.- Irudia: Cray 2 4 prozesagailu bektorialetako Superkonputagailua (1985). Jatorria infotology.
90. hamarkadan ordea, ehundaka konputagailuz osatutako superkonputagailuak agertu ziren (konputagailu Klusterrak), milaka prozesagailu zituztenak. 1993. urtean top500 zerrenda ere sortu zen, munduko 500 ordenagailu ahaltsuenak biltzen zituen zerrenda. Zerrenda honetako urte bakoitzeko ordenagailu ahaltsuena begiratuz, ikusi daiteke hainbat urtetan prozesagailu bektorial eta eskalarrak izan zirela zerrendako lehenengoak, txandakatuz. 1997. urterarte. Hortik aurrera prozesagailu eskalarrez eraikitako superkonputagailuak gailendu ziren.
Azpiko argazkietan, top500 zerrendan urteetan zehar, lehengoak izan diren hainbat superkonputagailu erakusten dira. Beraien tamaina denboran zehar nola handitu den ikus daiteke.
 2.- Irudia: Connection Machine 5 1024 prozesagailu eskalarretako superkonputagailua (1993). Jatorria infotology.
 3.- Irudia: Fujitsu Numerical Wind Superkonputagailua (1994). Superkonputagailu honek 140 prozesagailurekin, 3.680 preozesagailu zituen Intel Paragon XP/S140 superkonputagailua baino azkarragoa zen. Jatorria infotology .
Gaur egungo superkonputagailuak, beraz, konputagailu klusterrak dira, oinarrizko osagai batzuk dituzte, eta hauek milaka aldiz errepikatuta sortzen dira, unitate horiek, ordenagailu normal baten antzerakoak dira, prozesagailu eraginkorrago bat eta memoria gehiago izaten badute ere. Unitate guzti hauek sare egoki batez loturik daude, eta eraginkortasun handiko fitxategi sistema bat ere badute, datu irakurketa eta idazketa eraginkorra izan dadin. Askotan, biltegiratze sistema hau bera, beste superkonputagailu bat izan daiteke, datuak kalkulu superkonputagailuari abiadura handian eskura jartzen dizkiona. Ezaugarri hauek, osagai berdinekin, superkonputagailu txikiagoak eratzeko aukera ematen dute. Honegatik, top500 zerrendan dauden superkonputagailuetaz gain, ugariak dira oso antzeko osagaiekin eratuta dauden superkonputagailuak, tamaina, txikiagoak. >100.000 prozesagailu izan beharrean, milaka batzuk besterik ez dituzte, baina ikertzaile askorentzat nahikoak direnak. Superkonputagailu txikiago hauek eta top500-ekoak nolabait desberdintzeko, “Eraginkortasun Handiko Konputagailuak” direla esaten da, superkonputagailuak izatera iritsi gabe, naiz eta muga oso lausoa izan.
1.- Taula: Top500 zerrendan lehenengo posiziaon egon diren ordenagailuak (edo beraien familiak).
| Urtea |
Ordenagailua |
Prozesagaiuak |
Ahalmena (Rmax) TFLOPS |
|
| Ekainak 1993 |
TMC CM-5 |
1.024 Eskalarak |
0,1 |
|
| Azaroak 1993 |
Fujitsu Numerical Wind Tunnel |
140 Bektorialak |
0,12 |
|
| Ekainak 1994 |
Intel Paragon XP/S140 |
3.680 Eskalarrak |
0,14 |
|
| Azaroak 1994 |
Fujitsu Numerical Wind Tunnel |
140 Bektoriala |
0,17 |
|
| Ekainak 1996 |
Hitachi SR2201 |
1.024 Pseudo-Bektoriala |
0.22 |
|
| Azaroak 1996 |
Hitachi CP-PACS |
2.048 Pseudo-Bektoriala |
0,37 |
|
| Ekainak 1997 |
Intel ASCI Red |
7.264 (9.632) Eskalarra |
1 (2.3) |
|
| Azaroak 2000 |
IBM ASCI White |
8.192 Eskalarra |
4,9 |
|
| Ekainak 2002 |
NEC Earth Simulator |
5.120 Bektoriala |
35 |
|
| Azaroak 2004 |
IBM Blue Gene/L* |
32.768 (212.992) Eskalarra |
70 (478) |
|
| Ekainak 2008 |
IBM Roadrunner |
122.400 Eskalarra |
1.026 |
GPU |
| Azaroak 2009 |
Cray Jaguar |
224.162 Eskalarra |
1.759 |
|
| Azaroak 2010 |
NUDT Tianhe-1A |
186.368 Eskalarra |
2.566 |
GPU |
| Ekainak 2011 |
Fujitsu K computer |
548.352 Eskalarra |
8.162 |
|
| Ekainak 2012 |
IBM Sequoia Blue Gene/Q |
1.572.864 Eskalarra |
16.324 |
|
| Azaroak 2012 |
Cray Titan |
560.640 Eskalarra |
17.590 |
GPU |
| Ekainak 2013 |
NUDT Tianhe-2 |
3.120.000 Eskalarra |
33.862 |
Koprozesadorea |
* 2004-2008 urteetan zehar hainbat Blugene/L egon ziren top500 zerrendan lehengo.
1. Taula begiratuz, aipagarria da ere Azaroak 2010-eko Tianhe-1A superkonputagailuak GPU-ak zituela. GPU-a azken urteotan sortu den teknologia berri bat da, eragiketa grafikoak egiteko erabiltzen diren txartel grafikoetan oinarritua dago. Gaur egungo superkonputagailu hauetako askok horrelako prozesagailu arruntaz gain GPU-ak ere badituzte kalkulu ahalmena asko handitzen dutelarik. GPU-a prozesagailuaren kanpotik dagoen koprozesagailu bat bezala uler daiteke, eragiketa matematikoak oso azkar egiten prozesagailu nagusia laguntzen duena. Une honetan lehenengoa den Tianhe-2 ordenagailuak, Intelek sortutako xeon phi koprozesagailuak erabiltzen ditu, GPU-ekin zerikusirik ez dutenak baina bai helburu berdina.
Gaur egungo arazo nagusietako bat, superkonputagailu hauetako batek behar duen energia da. Irtenbide bat mugikorretan edo tabletetan erabiltzen diren prozesagailuak eta GPU-ak erabiltzea izan daiteke. Prozesagailua hauek, ez dira gaur egun konputagailuetan erabiltzen direnak eraginkorrak, energi gutxi behar dute ordea. Honela, adibide moduan, MontBlanc proiektua dago martxan, helburua exascale superkonputagailu bat lortzea da (1 exaFlop/s-tako ahalmena lukeena) baina gaur egungo konputagailu batek behar duen energia baino 15/30 aldiz gutxiago erabiliz.
Se ha realizado una conexión con un ancho de banda suficiente como para retransmitir 1.6 millones de películas en alta definición por vídeo streaming. Esta conexión de 8 terabits por segundo (Tbps), 8 millones de megas, de ancho de banda es la conexión de larga distancia a través de un supercanal óptico que ha conseguido realizarse entre las ciudades de Amsterdan (Holanda) y Hamburgo (Alemania). Para ello han utilizado la tecnología de Intelligent Transport Network de Infinera.
Topología de la red troncal de GÉANT La conexión ha sido establecida por DANTE (Delivery of Advanced Network Technology to Europe) que es la organización europea para la construcción y operación de la infraestructura de interconexión de alta velocidad entre instituciones europeas de investigación. Así pues, DANTE gestiona la conexión de entidades que incluyen universidades, centros de investigación e infraestructuras científicas (como por ejemplo el CERN). Este récord se ha implantado en la red GÉANT, que es la red física pan-europea que interconecta las redes nacionales de investigación y educación. GÉANT conecta entre si a 10.000 instituciones y 50 millones de investigadores.
Este anuncio se une al que realizó DANTE recientemente informando que había completado la principal actualización de la red GEANT a 2 Tbps para mejorar el acceso a recursos computacionales. Mas de 1000 terabytes (1 byte = 8 bits) circulan diariamente por red troncal IP de GEANT. La generación de datos científicos, su análisis y compartir los mismos está poniendo a prueba las e-infraestructuras compuestas por redes de comunicación, computación de altas prestaciones y grids. Datos generados por proyectos internacionales como el Gran Colosionador de Hadrones (LHC) del CERN, el futuro mayor telescopio del mundo, el Square Kilometre Array, o aplicaciones bioinformáticas generan cantidades masivas de datos que es necesario distribuir, analizar, almacenar y acceder. La red GEANT tiene una importancia central, en esta tarea, a nivel Europeo.
El proyecto de actualizar la red GEANT a supuesto una inversión a largo plazo, la renovación de 50.000 Km de la red troncal y la sustitución de equipamiento antiguo por tecnologías punteras en transmisión. La nueva tecnología permitirá nuevos servicios y mayor fiabilidad para garantizar un servicio continuo.
The course provides know-how and bioinformatics resources for assigning rich functional labels to high-dimensional sequence datasets and for extracting new knowledge from annotation data.
International Course in Automated Functional Annotation and Data Mining
Centro de Investigaciones Príncipe Felipe
Bioinformatics and Genomics Department
Avda. Autopista del Saler 16, Camino de las Moreras (Next to Oceanogŕafico)
46012 Valencia. Spain
23-25 of October, 2013
30 participants limit.
Early Bird Registration: 420 Euros (closes on the 23th of September)
Standard Registration: 550 Euros (closes on the 16th of October)
Registration web page.
More info
Information about the program, instructors, accommodation, what is included in the fee, etc in the web page of the course:
http://course.blast2go.com/home
According to the well known top500.org, list of the most powerful supercomputers in the world, today August 2013, the world’s most powerful computer is Tianhe-2 (Milky Way-2). This supercomputer is installed at the National University of Defense Technology (NUDT) in China and is the technological successor of Tianhe-1A, installed at the National Supercomputer Center in Tianjin, that already was No. 1 on the top500 list in November 2010. The top500.org list updates twice a year.
Tianhe-2 consists of 16,000 nodes each of which has 2 Intel Xeon Ivy Bridge processors and 3 Xeon Phi co-processors, to accelerate the calculations. This makes a total of 3,120,000 computing cores, 384,000 Xeon Ive Bridge cores and 2,736,000 cores in the Phi coprocessors. It is a novelty that it has 3 coprocessors per node, usually there are one or two. These cores provide to Tianhe-2 a theoretical peak performance running mathematical operations of 54.9 PFLOPS (Peta = 10 ^ 15 Floating-point Operation Per Second, 1,000,000,000,000,000 mathematical operations per second) and with the LINPACK benchmark the real performance reaches 33 .9 PFLOPS, which almost doubles the previous record of the Titan supercomputer located at the Oak Ridge National Laboratory (ORNL) in Tenessee.
Tianhe-2 Supercomputer The interconnection network between the nodes, namely TH Express-2, is a proprietary design firstly installed in Tianhe-2 and tries to avoid communications bottlenecks thanks to its bidirectional bandwidth of 16 GB/s, low latency and fat tree topology. Tianhe-2 uses the Kylin operating system based on Linux optimized for high performance computing and also developed by the NUDT. Being based on a standard Linux Kylin gives great flexibility to run many codes without specifically reprogram them.
Tianhe-2 consumes 17.8 MW, which is roughly equivalent to the consumption of 27,000 families. Nevertheless, it is energetically a very efficient supercomputer given the high number of FLOPS per watt it obtains. In the green500.org list of the energetically most efficient computers of the world Tianhe-2 is in the 32th position with 1,902 MFLOPS/W.
According to the NUDT Tianhe-2 will be dedicated to simulations, analysis and national security.
Most outstanding data
| Model |
Own design |
Nunber of cores
|
3.120.000: 384.000 Xeon Ivy-Bridge cores y 2.736.000 Phi cores |
| Processor |
Intel Xeon E-2692 with 12 cores at 2.2 GHz |
| Coprocessor |
Intel Phi 31S1P with 57 cores at 1,1 GHz |
| Interconection |
TH Express-2 |
| Operative System |
Kylin |
Theoretical FLOPS
|
54,9 PetaFLOPS |
Linpack FLOPS
|
33.9 PetaFLOPS |
Electric power
|
17.8 MW |
| FLOPS/W |
1.9 GigaFLOPS |
Note: This is a translation of our previous post in spanish “Tianhe-2, el ordenador más potente del mundo“.
La Red Gallega de Computación de Altas Prestaciones en colaboración con el CESGA, la Universidad de A Coruña y la Universidad de Santiago de Compostela organiza una serie de cursos gratuítos orientados a la formación de profesionales, profesores y estudiantes que quieran aprender a utilizar eficazmente los sistemas dedicados a la computación de altas prestaciones.
La consultora IDC pronostica que el mercado de sistemas de computación de altas prestaciones (HPC) crecerá en los próximos años un 7%. Es una oportunidad que requiere adquirir conocimientos de programación que permitan utilizar eficazmente estas infraestructuras de cómputo, que también sirven para aprovechar las arquitecturas de ordenadores disponibles en el mercado basadas en procesadores multi-núcleo, los coprocesadores basados en GPUs o el nuevo Xeon Phi de Intel.
Cursos
- Compilación, Ejecución y Optimización de Programas Científicos. Fechas: 9 y 10 de septiembre de 2013
- Programación en FORTRAN 90. Fechas: 11, 12 y 13 de septiembre de 2013
- Programación paralela utilizando directivas OpenMP. Fechas: 16,17,18,19 y 20 de septiembre de 2013
- Programación de GPUs con CUDA. Fechas: 7 y 8 de octubre de 2013
- Programación de Sistemas Heterogéneos con OpenCL. Fechas: 9 y 10 de octubre de 2013
- Introducción a la programación con MPI. Fechas: 21, 22, 23, 24, y 25 de octubre de 2013
Serán de 9:00 a 14:00 en el CESGA, Avenida de Vigo S/N, Campus Vida de Santiago de Compostela.
Dirigido a
- Desarrolladores de aplicaciones técnicas o de procesado de imágenes
- Científicos, ingenieros e investigadores que desarrollan aplicaciones numéricas o de procesado de imágenes.
- Personal técnico de apoyo a la optimización de aplicaciones numéricas.
- Profesores universitarios o de secundaria que quieran mejorar sus aplicaciones científico-técnicas.
- Alumnos universitarios que quieran aprender programación científica.
Requisitos previos
Es deseable que se tengan conocimientos básicos de:
- Programación.
- Arquitectura de computadoras.
Matrícula
- Registro: para cada curso se anuncia en la página WEB del CESGA
- Precio: 0€
La organización se reserva el derecho de cancelar el curso en caso de que no haya suficientes asistentes.
Más información y registro
Más información sobre los programas de los cursos y la inscripción en: https://www.cesga.es/es/soporte_usuarios/formacion/ver_cursos_abiertos
Regla mnemotécnica
bc: Basic Calculator
El comando bc es una calculadora que se puede usar dese la línea de comandos. Esta herramienta ofrece muchas posibilidades. En nuestro caso la presentaremos para realizar operaciones muy básicas, y más adelante veremos su utilidad en los scripts.
Si ejecutamos bc y entramos en su consola y podemos realizar operaciones y nos irá imprimiendo el resultado. Veamos un ejemplo:
$ bc
7+5
12
((7+5)/2)^2
36
1.1*3
3.3
quit
Su utilidad dentro de los scritps reside en la posibilidad de realizar operaciones utilizando las tuberías para pasarle operaciones matemáticas y que nos devuelva el resultado. veamos unos ejemplos:
$ echo 7+5*2 | bc
17
$echo (3^5-sqrt(16))/2 | bc
119
Podemos actualizar el valor de variables. Guardamos en actualizamos el valor de una variable con una operación matemática y=y+1 en la variable y:
$ y=1
$ y=$(echo $y+1 | bc)
$ echo $y
2
Expresiones mátemáticas en bash
Para trabajar con operaciones simples (+,-,* y /) y números enteros y asignarlo a variables es el comando let o la sintaxis $(( )). Veamos como reescribiríamos el ejemplo anterior con let:
$ y=1
$ let y=y+1
$ echo $y
2
y con la sintaxis para operaciones matemáticas
$ y=1
$ y=$((y+1))
$ echo $y
2
Estos dos comandos cuando trabajamos con números reales truncan el resultado y dan error si tratamos de escribir un número decimal. Así obtenemos el resultado el resultado incorrecto con:
$ y=$((7/4))
$ echo $y
1
en vez de 1.75 que es el correcto.
.
|
|

Comentarios