|
|
Superkonputazio edo Eraginkortasun Handiko Konputazioak (HPC – High Performance Computing ingeleraz) koputagailu eraginkor eta ahaltsuak erabiltzen ditu, bestela egiteko, oso astunak lirateken eragiketa matematikoak burutzeko. Azaro bukaeran atera berria den top500 zerrendako, adibide modura, Teide superkonputagailua aztertuz, segundo batean koma hikigorreko 340.000.000.000.000 eragiketa egin ditzakela ikusiko genuke (138.-a dago zerrendan eta 340 TFlops-etako ahalmena du). Zenbaki hau hobeto ulertzeko, har dezagun Camp Nou futbol zelaia, non 98.787 pertsona sartzen diren. Bete dezagun jendez eta eman diezaiogun kalkulagailu bat bakoitzari. Bakoitza, segundu batean eragiketa matematiko bat egiteko gai dela suposatuz, Teide superkonputagailuak segundo batean egiten dituen eragiketa kopuru bera egin ahal izateko, Camp Nou-ko pertsonek 110 urte beharko lituzkete!!!. Argi ikusten da, beraz, zein den konputagauilu hauen ahalmena. Muturretara joango bagina, Tianhe-2 (MilkyWay-2) une honetako konputagailu ahaltsuenaren eragiketa kopurua egiteko 17.000 urte beharko lirateke, eta beste muturrean, guk zerbitzuan dugun Arina HPC konputagailua, adibidez, eragiketa kopuru egiteko hiru urte inguru beharko lituzke jende horrek.
Tresna hauen ahalmen izugarria ikusi daiteke errez, baina zertarako erabiltzen da ahalmen guzi hori? Horretarako, EE.BB.-ko “Council on Competitiveness” erakundeak HPC (High Performance Computing, edo Eraginkortasun Handiko konputazioa) bultzatzeko honako bideoa egin du:
[youtube]http://www.youtube.com/watch?v=brwSYZQM5hc#t=57[/youtube]
Bertan, modu orokorrean, HPC erabilera ikusgarrienak aipatzen dira. Esate baterako:
- Hegazkingintza edo Espazio programak: aerodinamika, bidai tokien bentilazioa, motorren garapenerako …
- Olio eta Gas Industria: lurraren ezaugarri geologikoen azterketa ustiaketa merkeagotzeko …
- Energi berriztagarrien garapenerako …
- Autogintzan: Motor eraginkorragoak egiteko, hauen kutsadura maila gutxitzeko, segurtasuna handitzeko, gurpilen ezaugarriak hobetzeko, bidaiarien erosotasuna handitzeko, edo konpetizio auto azkarragoak sortzeko …
- Eguneroko tresenen garapena: diseinuen hobekuntza (leku gutxiago betetzen duten ontziak…), produktuak azkarrago merkaturatzeko …
- Natur fenomenoen ikerketarako hauek hobeto ulertu eta kalteak minimizatzeko …
- Kirolarien eraginkortasuna hobetzeko …
- Entrenemimendu industria: Efektu bisualak zein animazioak ikusgarriagoak egiteko …
- Medikuntzan, tratamendu berriak garatzeko, epidemien hedapenak aurreikusteko, sendagai berriak garatzeko …
Laburbilduz, HPC-aren garrantzia azpimarratzen da bideoan, eta bukaeran “High performance computing means High performance business and High Performance Lifes” hau da, “eraginkortasun handiko konputazioak, eraginkortasun handiko negozioa eta eraginkortasun handiko bizitza esan nahi du” esaldiarekin bukatzen dute, HPC-a Industrian bultzatzeko.
Bideoan aipatzen diren adibideak HPC arloko adibiderik ikusgarrienak izango dira ziur aski. Horiekin lotuta, aurreko hilabetean HPC buruzko ekitaldi batetan hainbat aldiz agertu zen Japonek HPC munduari eman dion bultzakada 2011. urteko Tohoku lurrikada eta ondorioz sorturtako tsunamiaren eraginez. Bertan hainbat bideo ikusgarri erakutsi zizkiguten K Superkonputagailuarekin lortuak (2011.-eko Azaroko top500 listan lehena jarri zen, gaur egun listako 4.-a da). Batzuk, sortutako tsunamiaren simulazioekin, olatuaren hedapena, eta lurrarekin izan zituen talka ugariak aztertuz, jasandako ondorioak etorkizunean nola minimizatu ikastea helburu dutenak. Beste batzuk, alerta egoera simulatu eta ebakuazioa modu eraginkorragoan nola egin aztertzen dabiltza, hauek ere naturaren indar hauen ondorioak gutxitzeko helburuarekin.
 2011-03-11-an Tohoku lurrikararen ondorioz sortutako tsunamiaren simulazioa. Jatorria: “Earthquake Research Institute, University of Tokyo, Prof. Takashi Furumura and Project Researcher Takuto Maeda. Animazio osoa hemen ikusi daiteke, eta informazio gehiago 201103 Tohoku web orrialdean. Guk eskeintzen dugun UPV/EHU-ko HPC zerbitzuan berriz, antzekotasunik duten ikerketak ere egiten dituzte gure erabiltzaileek. Hala ere, gure zerbitzuko ikertzaile gehienak, oinarrizko ikerketa egiten dute eta batez ere kimika eta fisikariak dira hauek. Hurrengo posten batean, laburtuko dugu gure baliabideekin egiten den ikerketa.
1 The Council on Competitiveness : EE.BB.tako erakunde bat da. 1986 urtean sortu zen, Lehiakortasunerako Kontseilua, gobernuz kanpoko erakunde ez partidista da. Partaideak EE.BB.-tako hainbat enpresetako CEO-ak, unibertsitateko errektoreak, lan-liderrak eta Laborategi Nazionaleko zuzendariek dira. Helburu nagusia EE.BB-tako lehiakortasuna sustartzea da, bitartean, politika publiko berritzaileak ezarriaz Amerika posperoago bat lortzeko.
La ley de Kurzweil es una extensión temporal y tecnológica de la Ley de Moore. Por todos es bien conocida la Ley de Moore que Gordon E. Moore enunció en 1965. Esta ley nos dice que el número de transistores que tiene un chip se dobla cada 24 meses, es decir, que la densidad de transistores en los chips se duplica cada dos años. Dado que además se dan otras mejoras tecnológicas, esto se suele reflejar en que la potencia de los ordenadores se multiplica por 2 cada 18 meses. Una tendencia similar se aplica a otro tipo de dispositivos electrónicos como la red, la memoria, etc. Es más, si nos ceñimos a la lista de los ordenadores más potentes del mundo, top500.org, la potencia de estos se duplica cada 14 meses, en los últimos 20 años la potencia de los superordenadores se ha multiplicado por 500.000.
 Primer circuito integrado de la historia, de J. Kilby. La Ley de Moore tiene una gran relevancia porque predijo un crecimiento exponencial de la potencia de los ordenadores, y la electrónica en general, tan solo 7 años después de la creación del primer circuito integrado y esta se sigue cumpliendo con gran precisión casi 50 años después de enunciarla a pesar del enorme incremento supone una ley de crecimiento exponencial.
Si bien la Ley de Moore es muy conocida, no lo es tanto la Ley de Kurzweil. Esta Ley nos dice que la potencia de cálculo ha ido creciendo exponencialmente desde la creación de las primeras máquinas capaces de computar automáticamente mediante el uso de tarjetas perforadas a principios del siglo XX.
En la figura inferior se muestra la evolución temporal del número de operaciones por segundo que realizaban diferentes máquinas a un costo fijo. Como podemos observar las máquinas mecánicas a base tarjetas perforadas inventadas a principio del siglo XX fueron mejorando e incrementando su potencialmente durante 35 años hasta que las primeras máquinas con relés electromecánicos tomaron el relevo. Evidentemente, los relés electromecánicos responden mucho más rápido que los mecánicos y esta tecnología se usó durante un breve periodo hasta que en la década de los 40 fueron totalmente sustituidos por las válvulas de vacío, elementos totalmente electrónicos y que no dependen de lentos movimientos mecánicos. Las válvulas de vacío dieron paso tras dos décadas a los transistores, dispositivos equivalentes pero construidos con materiales semiconductores mucho más baratos, longevos, con consumos mucho menores, etc. con los que se construyeron las computadoras en la década de los 60. Y finalmente tras las tarjetas perforadas, los relés electromecánicos, las válvulas de vacío y los transistores llegamos al quinto paradigma tecnológico: el circuito integrado. En realidad, este representa un paso adicional en el que los transistores se han miniaturizado y se integran varios en el mismo dispositivo, la tecnología electrónica se ha basado en estos dispositivos desde 1970.
 Ley de Kurzweil Tras 40 años de evolución cada vez se ve más cerca el fin evolutivo de esta tecnología. La miniaturización de los transistores es el proceso fundamental que ha permitido el aumento de la potencia de estos dispositivos al poder integrar más transistores en la misma área, mantener el consumo eléctrico a raya, reducir las distancias en los elementos, etc. Pero parece que esta minitaturización va a encontrar no un límite tecnológico, sino con uno físico. El transistor, elemento fundamental de los circuitos integrados tiene dos modos en los que se puede cambiar y que lo hacen funcional: el estado de corte, cuando no pasa corriente por el transistor y el estado de operación cuando si pasa corriente. La miniaturización del transistor está llevando a que se construyan unos transistores tan pequeños que llegará un momento que la distancia entre la entrada y salida de la corriente será tan pequeña que será imposible colocar el transistor en modo de corte al no poder crear una barrera lo suficientemente eficaz como para impedir el paso de corriente. Esto es porque cuando la barrera se haga lo suficientemente pequeña en el modo de corte todavía habrá suficiente corriente debido al conocido efecto túnel de la mecánica cuántica, es decir, no será posible poner el transistor en modo de corte. Siempre ha sido difícil determinar cuando se llegará a este límite, ahora se sitúa en el año 2026. Esto no significa necesariamente el avance tecnológico se detendrá, sino que seguramente surgirá otro nuevo paradigma tecnológico que sustituya al agotado transistor tradicional. Las grandes compañías tecnológicas lo saben y trabajan en ver que tecnología despuntará y se posicionará como el próximo paradigma tecnológico.
Regla mnemotécnica
while: Mientras en ingles.
While
El comando while es una instrucción de control de flujo que permite ejecutar una serie de comandos repetidamente sobre la base de una condición dada, es decir, genera un bucle. Cuando la condición deje de cumplirse, la ejecución del programa saldrá del bucle y no realizará más iteraciones. En los bucles while siempre hay que asegurarse de que siempre exista la condición que nos sacará del mismo, sino, entraremos en los peligrosos bucles infinitos donde se ejecuta la secuencia infinitamente. En caso de suceder esto es útil saber que podemos pulsar CTRL+C que mata el comando en curso.
Estructura del comando while
El comando while tiene la siguiente estructura
while [ condicion ]
do
comandoA
comandoB
done
donde los comandos entre do y done se ejecutan mientras se cumple la condición y se pueden poner tantos comandos como se desee. Si deseamos escribirlo en una línea este queda como:
while [ condicion ]; do comandoA ; comandoB ; done
Algunas expresiones que podemos usar como condición ya las ilustramos con el comando condicional if y puedes consultarlas en ese enlace. Se puede usar el comando continue para saltar a la siguiente iteración del bucle y el comando break para interrumpirlo. Veámoslo mejor con unos ejemplos.
Ejemplos Básicos
Aquí tenemos un bucle básico con while
i=1
while [ $i -le 10 ]
do
echo "Estamos en la iteración $i"
((i++))
done
donde se imprimirá en pantalla "Estamos en la iteración 1", 2, 3, etc. hasta 10. Cuando ya no se cumple que i es menor o igual (-le: less or equal) a 10 se sale del bucle. ((i++)) es equivalente a i=$(($i+1)) e incrementa el contador i en una unidad. Ahora vamos a ejecutar el mismo bucle pero saltándonos la iteración 4.
i=0
while [ $i -le 10 ]
do
((i++))
if [ $i == 4 ]
then
continue
fi
echo "Estamos en la iteración $i"
done
Vemos que cuando i==4 vuelve de nuevo al inicio del bucle y no ejecuta la orden echo. Es importante como hemos cambiado el incremento del índice i al principio del bucle. Si estuviese al final el bucle se quedaría ejecutándose infinitamente con el valor i=4. Si en vez del comando continue hubiésemos usado el comando break, en la iteración 4 habría terminado la ejecución del comando while, se rompe el blucle, y continuaría con el script. También podemos crear un bucle infinito y usar el comando break para salir de él. En el siguiente ejemplo si el fichero abort no existe el bucle se ejecuta infinitamente, en el momento en que se crea el fichero abort, se detecta mediante el if, se sale del bucle.
while [ 1 == 1 ]
do
echo "Estoy en el bucle."
if [ -f abort ]
then
echo "El fichero abortar exite. Saliendo..."
break
fi
done
Por supuesto, también se pueden ejecutar bucles anidados, unos dentro de otros, como en el siguiente ejemplo.
i=1
while [ $i -le 5 ]
do
#Para cada i un buble descendente hasta el valor i
j=5
while [ $j -ge $i ]
do
echo "Estamos en la iteración i=$i j=$j"
((j--))
done
((i++))
done
Ejemplos en un entorno de cálculo
Ejemplo 1: Ejecutar el comando qstat -u $USER cada 30 minutos, donde $USER es una variable de entorno que define al usuario. La ejecución del bucle no modifica la condición de salida por lo que estamos ante un bucle infinito.
a=1
while [ $a == 1 ]
do
qstat -u $USER
#Esperamos sin hacer nada 1800 segundos, 20 minutos
sleep 1800
done
Ejemplo 2: Mandar 10 trabajos (1.pbs, 2.pbs, …,10.pbs) a un sistema de colas PBS/Torque con el comando qsub:
x=10
while [ $x != 0 ]
do
qsub $x.pbs
x=$(echo $x-1 | bc)
done
o en una sola línea:
x=10; while [ $x != 0 ]; do qsub $x.pbs; x=$(echo $x-1 | bc); done
Regla mnemotécnica
case: En caso de en ingles in case.
Estructura del Comando Case
El comando case es una forma de ejecución condicional que nos permite ejecutar unos u otros comandos según el valor de una variable. No incluye ninguna funcionalidad nueva que no pueda ser realizada con el uso del comando if, pero en ciertos casos la sintaxis es más sencilla, intuitiva y directa. Con el comando case se lee una variable, si su valor coincide con alguno esperado se ejecutan los comandos asociados a ese valor. La sintaxis es como indicamos a continuación:
case $variable in
valor-1)
comandos
;;
valor-2)
comandos
;;
...
*)
comandos
esac
donde $varible es la variable que leemos, si tiene el valor-1 ejecuta los comandos que se encuentran a continuación hasta que se encuentran ";;" que indica el fin de los comandos asociados a ese valor de la variable. Se pueden definir cuantos posibilidades sean necesarias y como última opción podemos añadir el comodín "*)" y si la ejecución llega hasta este punto ejecutará los comandos para este caso. Si no existe "*)" y la variable no toma ninguno de los valores predefinidos evidentemente no se ejecuta nada. Veamos un ejemplo:
nombre=gabriel
case $nombre in
txomin) echo "No soy Gabriel"
echo "Soy Txomin"
;;
gabriel) echo "Soy Gabriel"
;;
*) echo "No soy Txomin"
echo "Ni tampoco soy Gabriel"
esac
Evidentemente la ejecución de este script dará como salida "Soy Gabriel" y es fácil ver que será lo que hará dependiendo del valor que le asignemos a la variable $nombre. También podemos usar el comando booleano “or” (o) con el símbolo “|” para indicar varios posibles valores asociados a los mismos comandos.
nombre=gabriel
case $nombre in
txomin|gabriel)
echo "Soy Gabriel o Txomin"
;;
*) echo "No soy Txomin"
echo "Ni tampoco soy Gabriel"
esac
Regla mnemotécnica
if: Conjunción si en ingles.
Estructura del condicional
El condicional if es un comando que nos permite ejecutar una secuencia de comandos dependiendo de la condición especificada. Con la misma podemos controlar la ejecución de un código en base a las necesidades establecidas por los condicionantes.
El modo mas simple de una sentencia condicional es:
if [ condición ]
then
comandos
fi
o en una única línea
if [ condición ] ; then comandos ; fi
En los siguientes ejemplos usaremos la primera sintaxis por ser más clara. En el ejemplo previo, si la condición se cumple se ejecutarán los comandos que introduzcamos hasta el cierre del condicional con fi. Hay que tener en cuenta que la condición ha de ir entre corchetes [ ] respetando los espacios en blanco entre los corchetes y la condición. Una versión algo más compleja puede incluir más posibles condiciones:
if [ condición-1 ]
then
comandos1
elif [ condición-2 ]
then
comandos-2
fi
donde elfi es una contracción de else if. Primero se evalua la condición-1 y si se cumple se ejecutan los comandos-1 y se sale del condicional, no se evalúan los siguientes. Si no se cumple la condición-1 se evalúa la condición-2 y si se cumple se ejecutan los comandos-2 y si no se sale del condicional. Se pueden escribir tantos elif como se desee. La última versión y más compleja estructura de condicional incluye la condición final else:
if [ condición-1 ]
then
comandos-1
elif [ condición-2 ]
then
comandos-2
else
comandos-3
fi
Aquí si no se cumple la condición-1 ni la condición-2 se entra en el else y se ejecutan los comandos-3. Veamos un ejemplo.
a=hola
if [ $a == 1 ]
then
echo "a es igual a 1"
elif [ $a == "adios" ]
then
echo "a es igual a adios"
else
echo "a nos es ni 1 ni adios"
fi
En este caso evidentemente veremos en pantalla el último mensaje “a no es ni 1 ni adios”. Observemos como la condición de igual se construye con dos signos [ a == 1] dado que con [ a = 1 ] lo que estamos haciendo es asignar a la variable a el valor 1. Algunos de los condicionantes más comunes son:
| == |
Igual que, tanto para números enteros como palabras |
| != |
Diferente que, tanto para números enteros como palabras |
| -eq |
Igual que (equal), sólo para números enteros |
| -ne |
Diferente que (non equal), sólo para números enteros |
| -gt |
Mayor que (greater than) |
| -ge |
Mayor o igual que (greater or equal than) |
| -lt |
Menor que (less than) |
| -le |
Menor o igual que (less or equal than) |
| ! |
Negación, invierte el condicional |
| -f nombre |
El fichero regular nombre existe |
| -d nombre |
El directorio nombre existe |
Ejemplos
Tres breves ejemplos. En el primero verificamos si el fichero regular datos.txt existe y en ese caso lo mostramos:
if [ -f datos.txt ]
then
echo "datos.txt existe"
cat datos.txt
fi
En el segundo ejemplo verificamos si el fichero regular datos.txt no existe y en ese caso lo creamos vacío:
if [ ! -f datos.txt ]
then
echo "datos.txt existe"
touch datos.txt
fi
En el tercer ejemplo usamos la salida de un comando dentro del condicional. Para ellos listaremos en un columna los ficheros y directorios del directorio actual terminados en txt con el comando ls, le pasaremos el resultado con una tubería (|) al comando wc y contaremos con este el número de ficheros Para tratar la salida de un comando como variable este ha de ir dentro de $( ).
#Primero simplemente mostramos el resultado para verificar
ls *txt |wc
#Ahora ejecutamos el ejemplo de condicional
if [ $(ls *txt |wc) -gt 0 ]
then
echo "Existen ficheros txt. Los borramos"
rm *txt
fi
En este script hemos borrado los ficheros *txt y hemos evitado que el script de error en caso de no existir ninguno.
Condicionales complejas
Se pueden construir condicionales complegas donde se conjugan varias de ellas a través de los operadores los booleanos “y” &&, “o” (||) y negación (!), este último que ya hemos visto. Ilustrémolos con un par de ejemplos en los que usaremos comando date para obtener información sobre el día de hoy. Con “o” basta que se cumpla una de las dos condiciones :
#Asignamos a la variable today el día de la semana.
today=$(date +%A)
#Evaluamos el condicional.
if [ $today == "lunes" ] || [ $today == "martes" ]; then
echo "Hoy es lunes o martes."
fi
Con “y” han de cumplirse ambas condiciones:
#Asignamos a la variable today el día de la semana.
dia=$(date +%e)
mes=$(date +%B)
#Evaluamos el condicional.
if [ $mes == "marzo" ] && [ $dia == "13" ]; then
echo "Hoy es mi cumpleaños."
fi
El operador && siempre se evalua antes que ||, pero se puede alterar esto agrupando los comando con paréntesis. Por ejemplo:
( [ cond-1 ] || [ cond-2 ] ) && ( [ cond-3 ] || [ cond-4 ] )
El término supercomputador surgió en la década de los 60, para describir el ordenador CDC 6600 que creó entonces la compañía Control Data Corporation (CDC). Este ordenador fue diseñado principalmente por Seymour Cray, que abandonó CDC en 1974 formando la empresa Cray Inc.
Las computadoras diseñadas por Cray tenían innumerables mejoras respecto a otros computadores de la misma época. Consideraban la paralelización a la hora de ejecutar códigos, y alcanzaba picos de rendimiento muy altos, la memoria y almacenamiento también era singulares. Al principio, estos supercomputadores eran máquinas individuales, con un único procesador y memoria que accedía el mismo. Más tarde, incorporaron varios procesadores, todos ellos accediendo la misma memoria. Los procesadores de estos supercomputadores eran vectoriales, y tenían un alto rendimiento en aplicaciones científicas, es decir en el Cálculo Científico. Podían realizar operaciones con vectores/matrices muy rápido y en pocos ciclos, ya que estos cabían en los registros del los procesadores.
Hasta la década de los noventa, fueron estos los supercomputadores más potentes del mercado. Los procesadores escalares que predominan hoy en día, realizan los cálculos con un único dato en cada ciclo. Los computadores Cray eran muy caros, costaban varios millones de dolares, y eran muy pocas las instituciones que podían contar con un supercomputador entre sus recursos para la investigación. Estos supercomputadores, aunque fueran unidades computacionales, eran grandes de tamaño (ver Fig 1).
En la década de los 90, la arquitectura de los supercomputadores cambio, y la unión de miles de ordenadores crearon los nuevos supercomputadores con miles de procesadores, los clusters de computación.
En 1993, se creó la lista del top500, donde aparecían los supercomputadores más potentes del momento. Mirando los ordenadores más potentes de ésta lista a largo de los años, vemos que durante algunos años se alternaron en el número uno los superordenadores con procesadores vectoriales y escalares. Hasta 1997, a partir de ese año, los procesadores vectoriales desaparecieron.
En las fotos de abajo se pueden ver algunos ordenadores que han estado en el top de la lista top500, en ellos se puede ver la evolución en el tamaño de los supercomputadores.
 - Figura 2.- Connection Machine 5 supercomputador con 1024 procesadores escalares. (1993). Fuente infotology.
 - Figura 3.- Supercomputador Fujitsu Numerical Wind (1994). Tenía 140 procesadores vectoriales, que eran más rápidos que los 3.680 escalares del supercomputador Intel Paragon XP/S140. Fuente infotology .
Los supercomputadores de hoy en día son clusters (granjas) de computadoras, miles de ordenadores que a través de unas redes especiales se unen en un supercomputador. Estas unidades, estos ordenadores que forman el supercomputador, son parecidas a los ordenadores normales que todos conocemos, eso sí, disponen de procesadores de alto rendimiento (para el cálculo científico), y normalmente también tienen más memoria que los ordenadores convencionales. Estas unidades están unidas por redes especiales, redes diseñadas específicamente para un superordenador concreto, redes del tipo cray, o algo más estándares como pueden ser infiniband y 10Gb Ethernet. A menudo también disponen de un sistema de almacenamiento de altas prestaciones, que puede ser otro cluster que se dedica únicamente a guardar los datos generados por la parte que se dedica al cómputo.
Estas características permiten crear supercomputadoras menores con los mismos componentes que los que pueden tener los que aparecen en la lista del top500. Estos superordenadores se quedarían en unos pocos miles de procesadores, pero suficientes para muchos investigadores. Para diferenciar estos superordenadores de menor tamaño, se suele usar el término de Computador de Altas Prestaciones, (HPC en inglés, de High Performance Computing), aunque es muy difícil de establecer el límite entre unos u otros.
Tabla 1.- Los primeros ordenadores (o sus familias) de la lista Top500 a lo largo de los años.
| Año |
Supercomputador |
Procesadores |
Potencia (Rmax) TFLOPS |
|
| Junio 1993 |
TMC CM-5 |
1.024 Escalares |
0,1 |
|
| Noviembre 1993 |
Fujitsu Numerical Wind Tunnel |
140 Vectoriales |
0,12 |
|
| Junio 1994 |
Intel Paragon XP/S140 |
3.680 Escalares |
0,14 |
|
| Noviembre 1994 |
Fujitsu Numerical Wind Tunnel |
140 Vectoriales |
0,17 |
|
| Junio 1996 |
Hitachi SR2201 |
1.024 Pseudo-Vectoriales |
0.22 |
|
| Noviembre 1996 |
Hitachi CP-PACS |
2.048 Pseudo-Vectoriales |
0,37 |
|
| Junio 1997 |
Intel ASCI Red |
7.264 Escalares (9.632) |
1 (2.3) |
|
| Noviembre 2000 |
IBM ASCI White |
8.192 Escalares |
4,9 |
|
| Junio 2002 |
NEC Earth Simulator |
5.120 Escalares |
35 |
|
| Noviembre 2004 |
IBM Blue Gene/L* |
32.768 (212.992) Escalares |
70 (478) |
|
| Junio 2008 |
IBM Roadrunner |
122.400 Escalares |
1.026 |
GPU |
| Noviembre 2009 |
Cray Jaguar |
224.162 Escalares |
1.759 |
|
| Noviembre 2010 |
NUDT Tianhe-1A |
186.368 Escalares |
2.566 |
GPU |
| Junio 2011 |
Fujitsu K computer |
548.352 Escalares |
8.162 |
|
| Junio 2012 |
IBM Sequoia Blue Gene/Q |
1.572.864 Escalares |
16.324 |
|
| Noviembre 2012 |
Cray Titan |
560.640 Escalares |
17.590 |
GPU |
| Junio 2013 |
NUDT Tianhe-2 |
3.120.000 Escalares |
33.862 |
Coprocesadores |
* Durante los años 2004-2008 fueron diferentes Blugene/L los que estuvieron en el top de la lista top500 con entre 32.786 y 212.992 cores. Algo similar ocurrió con ASCI Red.
Mirando la Tabla 1. llama la atención el Road Runner de 2008 y la aparición de las GPU (en este caso procesadores de Play Station) en su arquitectura, y cómo, a pesar de tener casi la mitad de procesadores que su predecesor (212.992), tiene más del doble de TeraFLOPS gracias a la potencia de las GPUs. Las GPUs son los compononetes especializados en cálculo gráfico para la representación de imágenes complejas en nuestros ordenadores, por ejemplo las de los videojuegos. La tecnología GPU para cálculo es una rama especializada en la utilización de esta tecnología para el cálculo científico. Las GPUs se pueden entender como una especie de coprocesador que se encuentra fuera de la CPU, y que ayuda a realizar operaciones matemáticas de una manera muy rápida y eficiente. Muchos de los supercomputadores actuales incluyen tarjetas GPUs. El Tianhe-2, supercomputador más rápido del momento, utiliza otro tipo de coprocesadores, que no tiene nada que ver con las GPUs, pero que cumplen con el mismo objetivo.
Uno de los principales problemas de la actualidad es el consumo energético de uno de estos supercomputadores (hablamos del tema en el post El top de los ordenadores más potentes del mundo, y la lista green500). Una solución para reducir éste consumo en la carrera hacia el ExaFLOPS, además del uso de GPUs, es el uso de procesadores de bajo consumo similares a los que se usan en teléfonos móviles o tablets. Estos procesadores no son tan potentes como los actuales, pero su eficiencia energética es mayor. El proyecto MontBlanc es un ejemplo, donde tiene como objetivo construir un supercomputador con potencia de 1 ExaFLOPS y un consumo en proporción 15/30 veces menor que los actuales.
Nota: Este post es básicamente una traducción del post Zer da Superkonputagailu bat? que publicamos en Euskera.
Memoria 2012
El Servicio de Informática Aplicada a la Investigación (Cálculo Científico) IZO-SGI SGIKer ha publicado la memoria del 2012. La memoria completa puede encontrarse en el siguiente enlace:
IZO-SGI informe del 2012 (pdf)
El IZO-SGI en cifras
En la siguiente tabla se resumen los datos más significativos del Servicio de cálculo en los últimos años. En la figura inferior se muestra la ocupación de Arina.
|
2009 |
2010 |
2011 |
2012 |
| Cores de cálculo |
440 |
872 |
1.520 |
1.520 |
| Millones de horas de cálculo consumidas |
2,11 |
2,26 |
5,76 |
11,27 |
| Investigadores activos |
101 |
98 |
90 |
89 |
| Grupos activos |
53 |
40 |
39 |
42 |
| Cuentas nuevas |
49 |
33 |
33 |
20 |
| Satisfacción de los usuarios¹ |
8.9 |
8.8 |
8.8 |
9,3 |
| Artículos científicos² |
44 |
58 |
57 |
74 |
| Visitas web |
4.925 |
5.957 |
8.022 |
9.899 |
| Páginas vistas |
58.731 |
40.987 |
30.042 |
30.738 |
| Posts en el blog HPC |
– |
29 |
34 |
27 |
| Visitas del blog HPC |
– |
1.431 |
3.818 |
4.741 |
| Arina |
|
|
|
| Cores de cálculo |
320 |
752 |
1.360 |
1360 |
| Millones de horas de cálculo consumidas |
2,07 |
2,11 |
5,20 |
9,6 |
| Promedio de ocupación |
75% |
47%³ |
74% |
79% |
| Trabajos enviados |
38.497 |
65.179 |
68.991 |
98.383 |
| Trabajos de más de 2 minutos⁴ |
28.377 |
50.624 |
51.735 |
78.846 |
| Tiempo promedio por trabajo⁵ |
76 horas |
44 horas |
101 horas |
122 horas |
| Tiempo medio de espera⁶ |
5,7 horas |
3,8 horas |
3,8 horas |
5,2 horas |
| Péndulo |
|
|
|
| Cores de cálculo |
120 |
120 |
120 |
80 |
| Millones de horas de cálculo consumidas |
0,02 |
0,15 |
0,09 |
0,07 |
| Ikerbasque |
|
|
| Cores de cálculo |
– |
– |
208 |
208 |
| Millones de horas de cálculo consumidas |
– |
– |
0,47 |
1,6 |
¹ Encuesta de satisfacción de los usuarios del Servicio realizada por la Unidad de Calidad de SGIker.
² En los que se agradece al IZO-SGI.
³ El uso de 2010 es aparentemente bajo debido a que se instaló una ampliación de Arina que pasó de 300 cores a 752 y se hizo disponible a finales de Julio. Esto provocó que en Agosto y Septiembre Arina estuviese muy vacía y, debido a la magnitud de la ampliación, estos meses han tenido mucho peso en la media anual. En el mes de Noviembre ya se alcanzó un 76% de ocupación.
⁴ Los trabajos de menos de 2 minutos se deben normalmente a trabajos fallidos que terminan inmediatamente en error. En cualquier caso, aun de no ser así, dada su corta duración no repercuten en el cluster.
⁵ No se han tenido en cuenta los trabajos de menos de dos minutos.
⁶ Los trabajos se ejecutan a través de un sistema de colas que asigna a cada trabajo los recursos que se le han solicitado y ordena su ejecución para optimizar el uso del cluster. El tiempo en cola es el tiempo que están esperando los trabajos hasta que se liberan los recursos que necesitan.
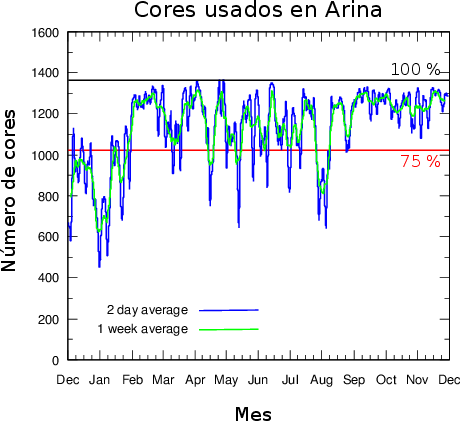 Uso de Arina de Diciembre de 2011 a Noviembre de 2012.
En Linux se pueden definir variables y arrays para facilitar la programación. La diferencia es que una variable almacena un dato mientras que un array almacena varios y se puede acceder a ellos individualmente.
Variables
Para asignar una variable usamos simplemente el nombre que queremos usar pero para mostrar su valor usamos el comando echo y la variable precedida del símbolo "$", para indicar que queremos que echo nos devuelva el valor de la variable y no el nombre que indicamos. Veamos unos ejemplos:
$ a=1
$ #Imprimimos la cadena literal a
$ echo a
a
$ #Imprimimos la varible a
$ echo $a
1
$ #Otros ejemplos
$ variable1=cascanueces
$ echo $variable1
cascanueces
$ kpj33='Entrecomillado para usar espacios'
$ echo $kpj33
Entrecomillado para usar espacios
$#Asignamos a una varible otra variable
$ a=xy
$ b=$a
$ echo $b
xy
$ #Con comillas simples no interpreta la variable
$ #en el siguiente ejemplo $a
$ c='La variable a tiene por valor $a'
La variable a tiene por valor $a
$ #En general en linux las comillas dobles
$ #si interpretan las variables
$ c="La variable a tiene por valor $a"
La variable a tiene por valor xy
Arrays
Los arrays tienen una sintaxis diferente para asignarlos a las variables, precisamene para poder diferenciarlos. Posteriormente se pueden mostrar los elementos uno a uno.El índice del primer elemento es el 0 no el 1. Veámoslo con unos ejemplos.
$ #v es una variable
$ v="a b c"
$ #a es un array
$ a=(a b c)
$ #Puedo imprimir la variable v
$ echo $v
a b c
$ #La misma sintaxis me imprimirá solo el primer elemento de un array
$ echo $a
a
$ #Que equivale a
$ echo ${a[0]}
a
$ #Para imprimir cualquier elemento
$ echo ${a[1]}
b
$ echo ${a[2]}
c
$ #Para imprimir todos
$ echo ${a[*]}
a b c
$ #Curiosamente se admiten expresiones matemáticas, para imprimir el elemento 2=1+1
$ echo ${a[1+1]}
c
La sintaxis de array solo funciona para variables, o si se aplica a una variable la interpreta como un array de un elemento
$ v="a b c"
$ echo ${v[0]}
a b c
$ echo ${v[1]}
$ #El elemento 1 ya no existe
Nos ha imprimido el resultado correcto en el primer caso, pero dado que no existe un segundo elemento en el segundo ejemplo no imprime nada. Por último, podemos obtener el número de elementos de un array “contándolos” con el símbolo "#":
$ v=(a b c d)
$ echo ${#v[*]}
4
Asignando la salida de un comando
Podemos utilizar la salida de un comando a modo de variable generalmene en cualquier contexto y en particular para asignarlo a una variable ejecutándolo entre $(). Para ellos usaremos el comando seq. Veamos un ejemplo de creación de una variable:
$ seq 1 5
1 2 3 4 5
$ v=$(seq 1 5)
$ echo $v
1 2 3 4 5
De forma similar para crear un array con la sintaxis de un array usando ():
$ v=($(seq 1 5))
$ echo ${#v[*]}
5
$ echo ${v[2]}
3
El Servicio General de Informática Aplicada a la Investigación-Cálculo Científico (IZO/SGI), que oferta servicios de computación a la UPV/EHU, la comunidad científica y empresarial, motivado por la fuerte demanda de sus investigadores va a ampliar sus recursos computacionales a través de concurso público que acaba de ser publicado ((PA 29/13) en el DOUE, BOE y en el Perfil del Contratante).
Índice
El IZO-SGI
Características de la futura ampliación
Characteristics of the upgrade (In English)
El IZO-SGI
El Servicio General de Informática Aplicada a la Investigación-Cálculo Científico (IZO/SGI) se creó el 2004 con la compra de las primeras unidades del que se denominaría Cluster Arina que constaba de 56 procesadores interconectados a través de una red Myrinet que se ha ido actualizando regularmente y la contratación de dos técnicos.
 Cluster de cálculo Arina trás 5 ampliaciones. Antes de la existencia del IZO/SGI, enmarcado dentro de los Servicios Generales de Investigación (SGIker), existían pequeños clusters y/o servidores pertenecientes a los grupos de investigación repartidos por la UPV/EHU. Esto obligaba a cada grupo tener que administrar sus propios recursos dedicando parte de su tiempo a ello, lo que reduce el tiempo disponible para la investigación. Por otra parte, cuando estos grupos no estaban utilizando sus computadoras (vacaciones o épocas sin calcular por diversos motivos), se puede considerar que perdían en la amortización de las mismas, ya que al estar paradas, su poder computacional estaba siendo desaprovechado mientras que las máquinas seguían envejeciendo.
El IZO/SGI libera a los grupos de investigación de tener que dedicar parte de su tiempo a la administración de un cluster y/o servidor y ofrece a los investigadores recursos que de forma individual no podrían tener. Los recursos están debidamente administrados y optimizados. Además, al ser un recurso compartido se garantiza que el uso de la máquina sea continuo al haber un altísimo número de investigadores usándola, por lo que su amortización es prácticamente óptima.
Los recursos del IZO-SGI se han convertido en la principal herramienta computacional para muchos grupos de la Universidad y también grupos externos. Algunos, incluso han dejado de comprar equipamiento propio, y es por eso que tenemos la necesidad de mejorar esta infraestructura ampliando sus recursos, con el fin de que los usuarios dispongan de herramientas óptimas para poder seguir desarrollando sus labores de investigación.
En la hoja de ruta del Servicio se estableció la conveniencia de ampliar los recursos cada dos años, para así poder ofrecer a los investigadores de la UPV/EHU y la CAV unos recursos óptimos y punteros en el ámbito de la Computación de las Altas Prestaciones, siempre y cuando la demanda lo exigiese. El periodo de actualización de dos años viene determinado por la rápida evolución del hardware informático que hace que los equipos pierdan mucho valor en dos años. Como referencia de esta evolución en los clusters de cálculo científico están las estadísticas del Top500, la lista de los ordenadores más potentes del mundo. De ésta se extrae que su potencia se duplica cada 14 meses desde 1993, o lo que es lo mismo, la competitividad de un cluster cae a la mitad cada 14 meses.
Características de la futura ampliación
Siguiendo con la hoja de ruta del Servicio y la demanda de recursos por parte de los investigadores del Servicio se ha aprobado una ampliación. Con esta ampliación se adquirirán mediante concurso público los siguientes equipos que pretenden cubrir las necesidades de los investigadores:
- Nuevos nodos de cálculo de propósito general para satisfacer la necesidad fundamental de potencia de cálculo.
- Un nodo con 512 Gb de memoria RAM orientado en concreto el ensamblaje procedente de secuenciación genética y a los cálculos más puntuales que necesitan mucha memoria.
- 2 nodos con GPGPUs para continuar dando soporte a los investigadores que actualmente la usan y tener un banco de test de esta innovadora tecnología.
- Un sistema de almacenamiento de altas prestaciones para el cálculo.
- Todo ello interconectado con una Infiniband FDR.
En la tabla 1 se detallan las ampliaciones más significativas del Servicio y algunas de sus características a grosso modo.
Tabla:
Ampliación de los recursos del IZO-SGI. Un core es técnicamente lo que antes se conocía como procesador.
|
|
|
| Año |
Ampliación Realizada |
|
| 2004 |
56 ia64 cores + Myrinet |
|
| 2006 |
72 cores (32 ia64 y 40 x86_64)+ Almacenamiento + infiniband |
|
| 2008 |
192 cores (ia64) + infiniband |
|
| 2010 |
448 cores (x86_64)+ Almacenamiento + GPGPU + infiniband |
|
| 2011 |
Ampliación con convenio con nanoGUNE |
|
|
648 cores (x86_64) + Almacenamiento + infiniband |
|
|
|
|
Characteristics of the upgrade
Following the road map of the Computing Service and the demand of more computational resources by the researchers of the Service has been approved to upgrade our computational resources. The following elements will be acquired through open competition in order to meet the requirements of the researches :
- New computing nodes to fulfill the general computing needs of the researchers.
- A 512 GB node focused in the assembly of genetic data and calculations with large memory needs.
- 2 nodes with GPGPUS to continue the support to the researches that use this technology.
- A High performance parallel files system.
- Everything interconnected with FDR Infiniband.
Computer power doubles every 18 months so todays smartphones, tablets and small electronic devices have a computer power comparable to the supercomputers of the early 90’s. The Fonebank infographic team has created this visual infographic with curios comparisons, milestones, information, etc. about the supercomputer’s world.
Full size infographic
 A supercomputer in you pocket infographic
|
|



Comentarios